Jekyll2025-12-08T13:03:55+00:00https://blog.cronn.de/feed.xmlwir bloggen über software_Im cronn Blog findet ihr Artikel zu Softwareentwicklung mit den neusten Technologien, zu coolen UI/UX-Designs, automatisierten Tests, aber auch zum Life-Style und Work-Life-Balance - alles "the cronn way".Setting Up an ML HPC Server (Part 1 - Hardware)2025-12-03T00:00:00+00:002025-12-03T00:00:00+00:00https://blog.cronn.de/en/machinelearning/2025/12/03/setting-up-ml-hpc-server-1Motivation
Many powerful AI models such as gpt-oss or DeepSeek are now published as open source. Powerful graphics cards (GPUs) are required in order to operate current and larger models at high performance. The decisive criterion here is the available graphics memory (vRAM).
High-end gaming GPUs are equipped with up to 24GB of vRAM. However, this is not sufficient for larger language models. Professional cards such as the NVIDIA H100 Tensor Core GPU have 80 GB of vRAM, but currently cost around €30,000.
Our goal was to build a machine learning computer on which medium-sized models could be operated locally without using cloud providers, which would be as powerful as possible, but on a manageable budget.
The choice fell on a Dell PowerEdge C4130 rack server with two Nvidia Tesla P40 GPUs, 64 Xeon cores, 128GB RAM and 800GB hot-swap disks. The acquisition costs for the used hardware amounted to a total of 1550 €.
In 2020 the P40 GPUs were in the upper performance class and continue to be provided with driver updates by Nvidia. How their performance has stood the test of time is revealed in the benchmarks in the second part of the article. For now we’ll describe the structure of the basic system without starting up the GPUs. The goal is to create a working environment that can be operated completely without physical access. The server hardware has some interesting featutres which allow such access, and we will now take a closer look at these features.
Initial assessment
The chassis of the C4130 is designed for mounting in a 19” rack, with a height unit (1U) and a depth of almost 90cm. It has 2 redundant 2 kW power supplies, one of which unfortunately suffered damage during shipping.
Delivery damage to the power supply.
While we had no issues with the seller exchanging the damaged goods, the matching C19 power cables were not included and had to be reordered.
The machine is completely designed for remote maintenance, so it usually no longer requires on-site presence after installation in the data center. It also has 2 Gigabit Ethernet ports and a maintenance port. It can be accessed via VGA and USB, but we do not use this due to the lack of a suitable VGA adapter. The handbook documents the various access routes.
When switched on for the first time, the LEDs on the front and back of the chassis flash orange. Ideally they should be solid blue, so the system doesn’t feel completely healthy.
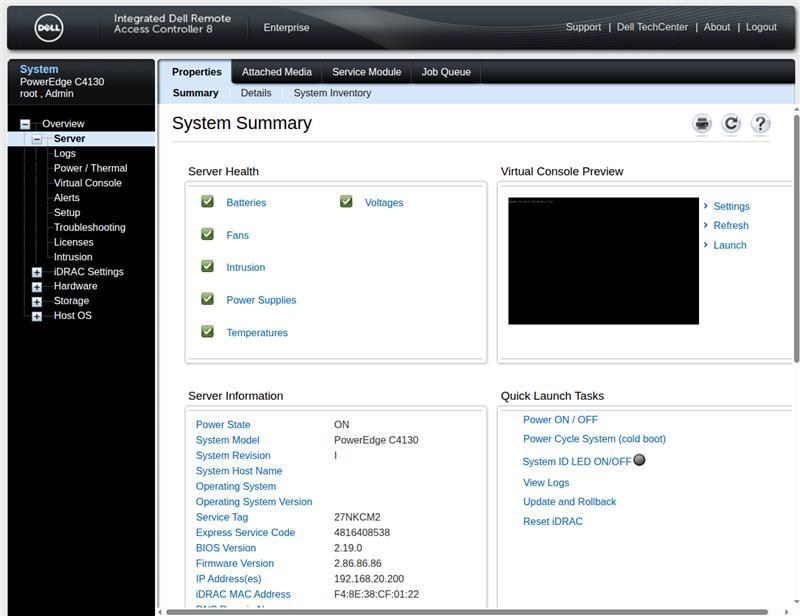
The maintenance access (iDRAC) has a somewhat old-fashioned web interface on the factory-set IP 192.168.0.120. Commendably, you can use the maintenance port on a switch as well as on a laptop (auto-sense), for which you have to manually select an IP address on the same LAN as the laptop.
The iDRAC is completely independent of the main system and can be accessed as soon as the chassis receives power. In the diagnostics area, the condition of all components is visible. In our case, as expected, the removed power supply is flagged, and a fan is also defective, which is why the status LEDs flash orange.
Speaking of fans: There are 8 built-in cooling units, each with 2 fans. Due to the low height (1U is about 4.5cm), they already spin at idle at 8,000 rpm. The limit is about 20,000 rpm, which is unpleasantly loud. Colleagues present in the room quickly left after it had been switched on.
Other interior features: a 128 GB main memory, 64 cores in 2 Xeon E5-2697A processors, and two 800 GB hot-swappable SSDs (1.8” uSATA).
When you remove the lid of the chassis, your eye is immediately caught by the 4 GPU bays directly in front of the fans. There are several slots free for more main memory, and there is still room for more hard drives at the back. The opening and reclosing of the chassis is logged by the iDRAC, even when it is switched off.
In the iDRAC there is a VNC console which allows access to the BIOS and other diagnostic tools. We performed a detailed memory test, which ended after several hours without returning any errors.
iDRAC interface has that look and feel of the 90s.
Before the first boot of the main system, we change the boot order in the BIOS and disable the default network start (PXE). Thanks to this we avoid long pauses at startup.
Before you can turn your attention to GPUs, a basic operating system is required. The choice fell on Ubuntu because it is both commonly used and supplied by Nvidia with current GPU drivers and libraries. We are looking for:
Encryption on both SSDs (cryptsetup + LUKS);
LVM with 2 physical volumes;
and within it logical partitions for /, /var and /home.
We decide against RAID1 on the hot-swappable disks in favor of more usable space for our AI models.
We start the Ubuntu server installer from a USB stick and access it via the VNC console in iDRAC. Caution is advised when entering passwords during installation: The keyboard layout of the VNC viewer in the iDRAC console is neither German nor English, but instead a wild mixture.
We noticed that the VNC console didn’t not run stable, with the connection not always working. A cold start might help.
The Ubuntu installer is somewhat overwhelmed with our partitioning requests: it apparently fails because the two encrypted disks are to be combined into one LVM volume (LVM = Logical Volume Manager). We work around the problem by initially setting up only an encrypted SSD with an LVM root volume. This means that the initial installation is complete within 5 minutes after a reboot.
LVM allows us to change volume sizes in the file system relatively easily afterwards, as well as to include additional disks. The necessary connections are already available in the chassis.
Manual setup of the second hard drive
We would like to have /home on the second (still unformatted) disk /dev/sdb, as we want to have plenty of room for our AI models. To do this, we create an encrypted partition:
To be able to unlock both disks with the same password, we use the script decrypt_keyctl (included in cryptsetup). It takes keyctl from the keyutils package, which we however still need to install manually. Then it is entered in /etc/crypttab for both disks:
The next time the machine is restarted, both disks are decoded as planned. We occupy the now available space entirely with /home in another physical LVM volume. In theory, LVM could be dispensed with for a single partition, however it allows us to change the distribution of the disks later if necessary.
Normally, the password for encrypted hard drives is required at system startup. However, this will no longer be accessible as soon as the machine is placed in the rack. We therefore install dropbear-initramfs to be able to unlock the disks via SSH.
Deviating from usual procedure, we convert the existing OpenSSH host keys to Dropbear format and install them in initramfs, so that we can use the normal SSH port (22) for unlocking without causing any key conflicts.
Finally, the public keys of all administrators are entered in /etc/dropbear/initramfs/authorized_keys and the ramdisk is updated:
# update-initramfs -u
# reboot
Et voilà, after a reboot, the disks can be unlocked via SSH.
Compulsory reworking
During the final system cleanup, we stupidly overlooked the fact that cryptsetup-initramfs is not a manually selected package and it is automatically uninstalled. As a result, the system no longer boots because the root partition cannot be decrypted.
Luckily a rescue system is hidden in the help menu of the Ubuntu installer. From there, we manually mount the installed filesystem and reinstall cryptsetup-initramfs in the chroot. Now the machine starts again.
]]>danielKnauthEinrichtung eines ML-HPC-Servers (Teil 1 - Hardware)2025-12-02T00:00:00+00:002025-12-02T00:00:00+00:00https://blog.cronn.de/de/machinelearning/2025/12/02/einrichtung-ml-hpc-server-1Motivation
Viele mächtige KI-Modelle wie gpt-oss oder DeepSeek werden mittlerweile als Open Source veröffentlicht. Um aktuelle und größere Modelle performant zu betreiben, werden leistungsfähige Grafikkarten (GPUs) benötigt. Ein maßgebliches Kriterium ist dabei der verfügbare Grafikspeicher (vRAM).
Gaming-GPUs der oberen Preisklasse sind mit bis zu 24 GB vRAM ausgestattet. Das ist für größere Sprachmodelle jedoch nicht ausreichend. Professionelle Karten wie die NVIDIA H100 Tensor Core GPU haben 80 GB vRAM, kosten aber derzeit ca. 30.000 €. Unser Ziel war es, mit überschaubarem Budget einen möglichst leistungsfähigen Rechner für Machine-Learning aufzubauen, auf dem mittelgroße Modelle lokal betrieben werden können, ohne Nutzung von Cloud-Anbietern.
Die Wahl fiel auf einen Dell PowerEdge C4130 Rack Server mit zwei Nvidia Tesla P40 GPUs, 64 Xeon-Kernen, 128GB RAM und 800GB Hot-Swap Platten. Die Anschaffungskosten für die gebrauchte Hardware betragen in Summe 1550 €.
Die P40-GPUs waren um 2020 in der oberen Leistungsklasse und werden weiterhin von Nvidia mit Treiber-Updates versorgt. Was man damit heute noch anfangen kann, verraten die Benchmarks im zweiten Teil des Artikels.
Der erste Teil beschreibt den Aufbau des Grundsystems ohne Inbetriebnahme der GPUs. Das Ziel ist, eine lauffähige Umgebung zu bekommen, die komplett ohne physischen Zugang betreibbar ist. Dafür hat die bestellte Server-Hardware einige interessante Eigenheiten, die wir näher betrachten.
Erstbegutachtung
Das Chassis des C4130 ist für Montage in einem 19” Rack bestimmt, es hat eine Höheneinheit (1U) und eine Tiefe von fast 90cm. Es besitzt 2 redundante 2 kW-Netzteile, von denen eines leider einen unübersehbaren Transportschaden hat.
Lieferschaden am Netzteil.
Ein Austausch durch den Händler erfolgt problemlos. Die passenden C19-Stromkabel liegen dummerweise nicht bei und müssen ebenfalls nachbestellt werden.
Die Maschine ist komplett für Fernwartung ausgelegt, also erfordert sie nach Einbau im Rechenzentrum (RZ) normalerweise keine Präsenz mehr vor Ort. Dazu hat sie 2 Gigabit Ethernet-Anschlüsse und einen Wartungs-Port. Man kann auch über VGA und USB darauf zugreifen, worauf wir mangels passendem VGA-Adapter jedoch verzichten. Im Handbuch sind die verschiedenen Zugangswege dokumentiert.
Beim erstmaligen Einschalten fallen die orange blinkenden LEDs an Vorder- und Rückseite des Chassis auf. Normalerweise sollten sie konstant blau leuchten, das System fühlt sich also nicht völlig gesund.
Der Wartungszugang (iDRAC) hat eine etwas altbackene Weboberfläche auf der werksseitig eingestellten IP 192.168.0.120. Löblicherweise kann man den Wartungs-Port sowohl an einem Switch als auch an einem Laptop benutzen (auto-sense), wofür am Laptop manuell eine IP im selben LAN gewählt werden muss.
Das iDRAC ist komplett unabhängig vom Hauptsystem und erreichbar, sobald das Chassis Strom bekommt. Im Diagnosebereich ist der Zustand aller Komponenten sichtbar, in unserem Fall wird erwartungsgemäß das ausgebaute Netzteil beanstandet, außerdem ist ein Lüfter defekt, weswegen die Status-LEDs orange blinken. Apropos Lüfter: Eingebaut sind 8 Stück mit jeweils 2 Ventilatoren. Aufgrund der geringen Bauhöhe (1U sind ca. 4,5cm) drehen diese schon im Leerlauf mit 8.000 U/min, das Limit sind ca. 20.000 U/min, also richtig unangenehm laut. Anwesende Kollegen verließen nach dem Einschalten zügig den Raum.
Weitere Innenausstattung: 128 GB Hauptspeicher, 64 Kerne in 2 Xeon E5-2697A-Prozessoren, zwei 800 GB hot-Swap-fähige SSDs (1,8” uSATA).
Wenn man den Deckel des Chassis abnimmt, fallen sofort die 4 GPU-Einschübe direkt vor den Lüftern ins Auge. Für mehr Hauptspeicher sind etliche Steckplätze frei, hinten ist noch Platz für weitere Festplatten. Das Öffnen und Wiederverschließen des Chassis wird vom iDRAC protokolliert, auch in ausgeschaltetem Zustand.
Im iDRAC gibt es eine VNC-Konsole, die u.a. Zugriff auf das BIOS und weitere Diagnose-Werkzeuge erlaubt. Wir machen einen ausführlichen Speichertest, der nach mehreren Stunden ohne Fehler endet.
iDRAC-Oberfläche im Look&Feel der 90er Jahre.
Vor dem ersten Start des Hauptsystems ändern wir noch die Boot-Reihenfolge im BIOS, denn dort ist Netzwerkstart (PXE) voreingestellt. Wir deaktivieren es, um lange Pausen beim Start zu vermeiden.
Linux-Basisinstallation
Bevor man sich den GPUs zuwenden kann, wird ein Basis-Betriebssystem benötigt. Die Wahl fiel auf Ubuntu, weil es gängig ist und von Nvidia mit aktuellen GPU-Treibern und –Bibliotheken versorgt wird.
Wir hätten gerne:
Verschlüsselung auf beiden SSDs (cryptsetup + LUKS),
darüber LVM mit 2 physischen Volumes,
und darin logische Partitionen für /, /var und /home.
Auf ein RAID1 der Hot-Swap-Platten verzichten wir zugunsten von mehr nutzbarem Platz für KI-Modelle.
Wir starten den Ubuntu-Server-Installer von einem USB-Stick und greifen über die VNC-Konsole im iDRAC darauf zu. Bei der Eingabe von Kennworten während der Installation ist Vorsicht geboten: Die Tastaturbelegung des VNC-Viewers in der iDRAC-Konsole ist eigenwillig, weder deutsch noch englisch, sondern eine wilde Mixtur.
Uns fällt auf, dass die VNC-Konsole nicht ganz stabil läuft, manchmal funktioniert der Verbindungsaufbau nicht. Ein Kaltstart kann weiterhelfen.
Der Ubuntu-Installer ist mit unseren Partitionierungswünschen etwas überfordert, es scheitert offenbar an den zwei verschlüsselten Platten, die zu einem LVM-Volume (LVM = Logical Volume Manager) zusammengefasst werden sollen. Wir umgehen das Problem, indem wir zunächst nur eine verschlüsselte SSD mit einem LVM Root-Volume einrichten. Damit ist die Erstinstallation in 5 Minuten nach einem Neustart abgeschlossen.
LVM erlaubt uns, nachträglich die Volume-Größen im Dateisystem relativ einfach zu ändern oder zusätzliche Platten einzubinden. Dafür sind im Chassis die passenden Anschlüsse bereits vorhanden.
Manuelle Einrichtung der zweiten Festplatte
Wir hätten gerne /home auf der zweiten (noch unformatierten) Platte /dev/sdb, da wir reichlich Platz für KI-Modelle haben wollen. Dazu legen wir eine verschlüsselte Partition an:
Um beide Platten mit demselben Passwort entsperren zu können, benutzen wir das Skript decrypt_keyctl (in cryptsetup enthalten). Es benötigt keyctl aus dem Paket keyutils, das wir noch manuell installieren müssen. Anschließend wird es für beide Platten in /etc/crypttab eingetragen:
Beim nächsten Neustart der Maschine werden wunschgemäß beide Platten entschlüsselt. Den nun verfügbaren Platz belegen wir vollständig mit /home in einem weiteren physischen LVM-Volume. Auf LVM könnte man für eine einzelne Partition im Prinzip auch verzichten, aber es erlaubt uns, gegebenenfalls später die Aufteilung der Platten zu ändern.
Normalerweise wird beim Systemstart das Kennwort für verschlüsselte Festplatten auf der Konsole verlangt. Diese wird jedoch nicht mehr zugänglich sein, sobald die Maschine ins Rack kommt. Wir installieren daher dropbear-initramfs, um die Platten über SSH entsperren zu können.
Abweichend von der üblichen Vorgehensweise konvertieren wir die vorhandenen OpenSSH Host Keys ins Dropbear-Format und installierten sie ins initramfs, so dass wir zur Entsperrung den normalen SSH-Port 22 ohne Schlüsselkonflikte nutzen können.
Zuletzt werden öffentliche Schlüssel der Administratoren in /etc/dropbear/initramfs/authorized_keys eingetragen und die Ramdisk aktualisiert:
# update-initramfs -u
# reboot
Voilà, nach einem Neustart lassen sich die Platten auch über SSH entsperren.
Unfreiwillige Nacharbeiten
Bei der abschließenden Bereinigung des Systems übersehen wir dummerweise, dass cryptsetup-initramfs kein manuell gewähltes Paket ist und automatisch deinstalliert wird. Daraufhin startet das System nicht mehr, weil die Root-Partition nicht entschlüsselt werden kann.
Ein vollständiges Rettungssystem ist im Hilfemenü des Ubuntu-Installers versteckt. Von dort hängen wir das installierte Dateisystem manuell ein und installieren cryptsetup-initramfs im chroot noch einmal. Nun startet die Maschine wieder.
Für den nächsten Schritt montieren wir die P40-GPUs in die Einschübe 1+2. Deren Einrichtung und die Messung der Rechenleistung werden im zweiten Teil beschrieben.
]]>danielKnauthSicherheit automatisiert testen: Mit Playwright zu robuster Web Security2025-11-13T00:00:00+00:002025-11-13T00:00:00+00:00https://blog.cronn.de/de/testing/2025/11/13/security-e2e-testsEinleitung
Mit automatisierten Ende-zu-Ende-Tests lassen sich nicht nur Bugs finden, sondern auch regelmäßig die Einhaltung von Sicherheitsmaßnahmen überprüfen. Das hat eine Reihe von Vorteilen:
Automatisierte Security-Tests überprüfen zuverlässig, ob Sicherheitsfunktionen wie vorgesehen funktionieren.
Sie helfen dabei, Sicherheitsmechanismen während der Weiterentwicklung stabil zu halten und ungewollte Regressionen frühzeitig zu erkennen.
Beim Schreiben automatisierter Tests wird die Perspektive potenzieller Angreifer eingenommen.
In diesem Artikel zeigen wir anhand konkreter Beispiele, wie sich mit Playwright sicherheitsrelevante Aspekte wie Content Security Policy (CSP), Clickjacking oder Cross-Site Request Forgery (CSRF) zuverlässig testen lassen.
Ansatz: Playwright-Ende-zu-Ende-Security-Testing
In diesem Artikel werden wir uns auf die Überprüfung ausgewählter Sicherheitsaspekte mithilfe von automatisierten Ende-zu-Ende-Tests konzentrieren. Diese Tests können neben den Ende-zu-Ende-Tests für die Features der Anwendung implementiert werden. Sie können in der gleichen Pipeline laufen wie diese „normalen“ Tests. Daher fühlt sich ihre Entwicklung wie die Entwicklung der Tests für Anwendungsfeatures an. Wir zeigen in diesem Beispiel exemplarisch für Content Security Policy (CSP) wie man einige Aspekte mithilfe von Playwright überprüfen kann. Die CSP wird im Header einer HTML-Antwort verschickt. Sie wird während der Entwicklungsarbeiten des Frontends konfiguriert. Um die CSP zu überprüfen, bietet es sich daher an, im Rahmen eines Tests, die Seite aufzurufen und dort die Checks durchzuführen. Playwright ist für Ende-zu-Ende Tests einer Webapplikation derzeit das gängige Werkzeug. Hier werden wir speziell auf die Besonderheiten beim Testen der CSP mit Playwright eingehen. Im Großen und Ganzen können für die Sicherheitstests die gleichen Ansätze und Methoden verwendet werden wie für Ende-zu-Ende Tests für neue Features.
In unseren Tests für die CSP wollen wir verschiedene Aspekte überprüfen.
Content-Security-Policy-Überprüfung
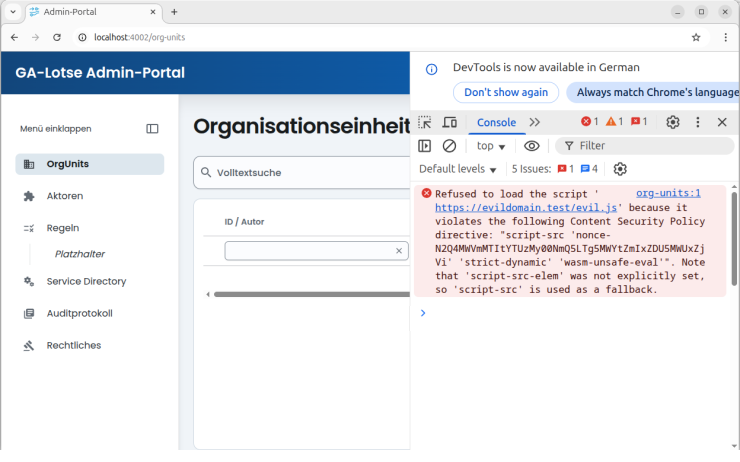
Der erste Aspekt betrifft das einfache Aufrufen der zu überprüfenden Seite. Hier wollen wir als Erstes sicherstellen, dass keine CSP durch die vorhandene Implementierung verletzt wird. Daher rufen wir die Seite auf und überprüfen, dass keine Warnung in der Konsole des Browsers erscheint. Mit einer kleinen Funktion können wir Playwright anweisen, die Fehlermeldungen der Browserkonsole, die während des Tests erzeugt werden, in ein Array zu schreiben. Dazu übergeben wir die Seite und das Array an die Funktion und deren Implementierung sorgt dafür, dass die Fehlermeldungen in unser Array geschrieben werden.
Wir können daher nach dem Aufruf unserer zu überprüfenden Seite validieren, dass keine CSP-Warnungen oder andere Fehlermeldungen auf der Seite ausgelöst wurden. Die Überprüfung kann mit der expect-Funktion von Playwright vorgenommen werden.
expect(errors).toHaveLength(0);
Beim Aufrufen der Seite durch Playwright erhalten wir auch die Antwort auf diesen Aufruf. Diese enthält im Header die CSP-Attribute. Wir schreiben diese Werte in eine sogenannte Validierungsdatei. Diese wird beim ersten Durchlaufen des Tests mit den aktuellen CSP-Attributen gefüllt. Diese Werte müssen initial auf die erwarteten Werte kritisch überprüft werden. Sollte es Abweichungen zu den erwarteten Werten geben, so muss die CSP angepasst werden, damit die Werte in der Validierungsdatei mit den erwarteten Werten übereinstimmen.
Sobald die Validierungsdatei freigegeben worden ist, wird in jedem weiteren Durchlauf des Tests, ob lokal oder in einer Pipeline, der Inhalt der Datei mit den aktuell erhaltenen Attributen verglichen. Sollte eine Abweichung erkannt werden, schlägt der Test fehl. Auf diese Weise werden zuverlässig alle Änderungen an der CSP erkannt. Bei geplanten Änderungen der CSP kann die Datei angepasst werden. In den restlichen Fällen wird überprüft, warum sich die CSP geändert hat und es kann entschieden werden, ob die Änderung rückgängig gemacht werden muss oder ob sie beibehalten werden kann.
Hier ist ein Beispiel, wie der Inhalt einer solchen Validierungsdatei aussieht:
Die Nonce-Werte haben wir in dieser Datei maskiert, da sie in jedem Durchlauf neu erzeugt werden und der Test daher nicht auf einen konkreten Nonce-Wert testen kann.
asyncfunctionvalidateCSPData(response:Response,page:Page,){constcspHeaderValues=(awaitresponse.allHeaders())["content-security-policy"]??"";if(cspHeaderValues===""){thrownewError("CSP must not be empty.");}consthasMetaCSP=awaitcheckMetaCSP(page);expect(hasMetaCSP).toBeFalsy();constsnapshot:Record<string,string[]>={};snapshot.cspHeaderValues=cspHeaderValues.split(/;\s*/).filter((str)=>str!=="");awaitcompareActualWithValidationFile(snapshot);}
In der gezeigten Methode validateCSPData ist unsere Implementierung für die Validierung der CSP-Attribute zu sehen. Wir müssen der Methode lediglich die Seite (page) und die Antwort des Aufrufs der Seite (response) übergeben. Die Methode extrahiert aus der Antwort den Anteil, der die CSP betrifft. In einer ersten Validierung überprüfen wir, dass die CSP nicht leer ist. Wir führen dann eine weitere Überprüfung aus und validieren, dass keine Meta-CSP-Attribute im HTML-Teil der Antwort befindlich sind. Wir haben uns dazu entschieden als eigenen Standard keine Meta-CSP-Attribute zuzulassen und überprüfen das an dieser Stelle, um Konflikte zwischen der CSP im Header und in den Meta-Attributen zu vermeiden. Am Ende der Methode formatieren wir die CSP-Attribute und übergeben sie unserer Methode, die die Werte mit der oben erwähnten Datei vergleicht.
CSP-Warnung überprüfen
In einem weiteren Schritt manipulieren wird den HTML-Teil unserer zu überprüfenden Seite und verifizieren, dass die erwarteten CSP-Warnungen in der Konsole des Browsers erscheinen.
Eine Manipulation enthält zum Beispiel folgende Zeile, die wir dem HTML-Body der Seite hinzufügen:
Diese Manipulation simuliert einen Angriff per XSS (Cross-Site-Scripting). Bei einem solchen Angriff wird auf eine Website „bösartiger Code“, meist in Form von JavaScript, eingeschleust. Falls der Code zur Ausführung käme, könnten zum Beispiel sensible Daten abgegriffen werden. Daher ist es wichtig zu überprüfen, dass falls Code in die Seite eingeschleust werden sollte, dieser auf keinen Fall ausgeführt wird.
Die Manipulation des HTML-Bodys erreichen wir mithilfe der Methode route, die wir auf das page-Objekt von Playwright anwenden:
In dieser Methode manipulieren wir den Aufruf der zu überprüfenden Seite. Wir wenden die route-Methode auf die URL der Seite an und manipulieren dabei den HTML-Body. In der route-Methode geben wir als ersten Parameter die URL an, die wir manipulieren möchten. Als zweiten Parameter definieren wir die Anweisungen, die dazu führen, dass der Body manipuliert wird. Dazu lassen wir zuerst mittels route.fetch die eigentliche Antwort auf Anfragen zu der zu testenden Seite in eine Variable speichern. Diese Antwort verändern wird dann, indem wir am Ende ein „böses“ Skript hinzufügen. Mittels route.fulfill weisen wir Playwright an, beim Aufruf der Seite den manipulierten Body zurückzugeben.
Nachdem die Methode im Test aufgerufen worden ist, wird jeder Aufruf der Seite von Playwright abgefangen und der HTML-Body der Antwort wird durch den manipulierten Body ersetzt.
Für den Fall, dass durch eine unzureichende CSP das Skript aufgerufen werden sollte, verwenden wir auch die route-Methode von Playwright. Diese leitet den Aufruf für das Skript auf ein von uns definiertes Skript um:
Wenn während der Testausführung die Seite mit dem manipulierten Body aufgerufen wird, wird eine Warnung in der Konsole des Browsers ausgegeben und das „böse“ Skript wird nicht geladen.
Man kann in dem Screenshot, der während der Testausführung erstellt wurde, mehrere verletzte CSP-Regeln sehen. Diese Fehlermeldungen werden in das anfangs erwähnte Array geschrieben. Sie werden wie die CSP im Header der HTML-Antwort in einer separaten Datei validiert. Sollte sich während einer Testausführung die Fehlermeldung ändern oder ganz ausbleiben, schlägt der Test fehl und es muss nach einer Ursache sowie einer Lösung dafür gesucht werden.
Clickjacking mittels CSP verhindern
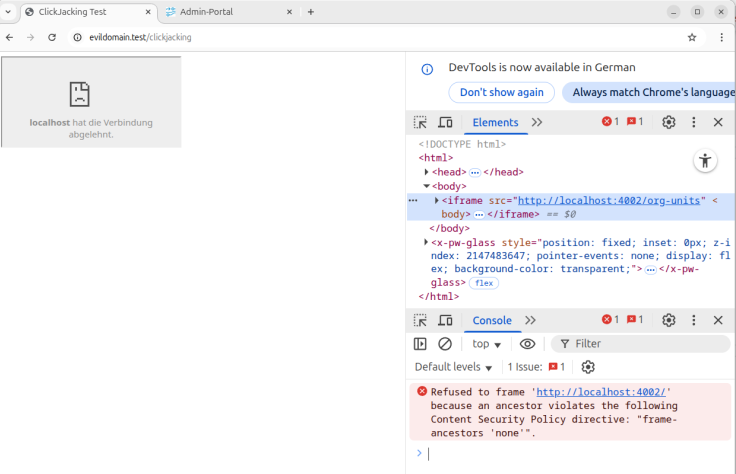
Mithilfe der CSP kann auch verhindert werden, dass „bösartige“ Websites unsere Seite mittels eines iframe Elements in ihre Website einbetten, ein sogenannter Clickjacking-Angriff. Durch die Einbettung der Website wird unsere Seite durch die bösartige Website überlagert und weder die User noch wir als Betreiber erkennen, dass ungewollt Funktionen auf der Seite ausgeführt werden. Um dies zu verhindern, wird der CSP „frame-ancestors `none`“ hinzugefügt. Dies sorgt dafür, dass die Einbettung auf anderen Websites fehlschlägt. Für unseren Test haben wir eine minimale Website erstellt, die ein iframe-Element auf unsere Seite enthält. Wir haben dazu wieder die route-Methode verwendet.
Die Methode setupRouteForIframeSite führt dazu, dass wenn im Test die URL „https://bad.test/clickjacking“ aufgerufen wird, die in der Methode definierte Seite aufgerufen wird. Wenn die CSP korrekt konfiguriert ist, dann funktioniert das iframe-Element nicht. Zudem wird auf der Seite eine Fehlermeldung in der Konsole ausgegeben.
Das ist in dem obigen Screenshot zu sehen. In der Fehlermeldung wird auch die verletzte CSP „frame-ancestors 'none’“ angegeben. Auch diese
Fehlermeldung wird wie oben beschrieben in eine Validierungsdatei geschrieben und bei jeder Ausführung des Tests überprüft.
CSRF-Angriff testen
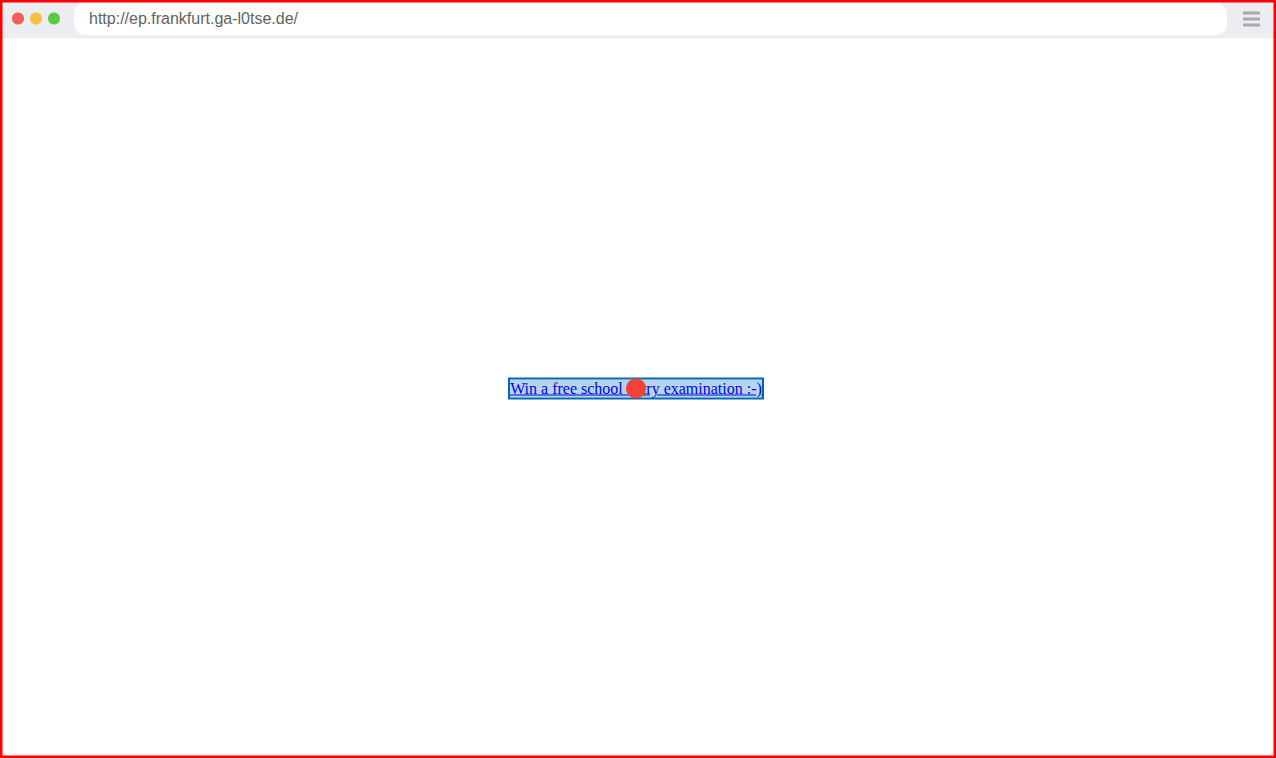
Zum Abschluss stellen wir noch ein CSRF-Szenario vor, welches man mittels Ende-zu-Ende-Tests in Playwright überprüfen kann. In einem ersten Schritt loggt sich der Playwright Test bei der zu testenden Software ein. Wir haben für diesen Test zwei minimale Websites erstellt, die bei dem Klick auf einen Link eine Abfrage an unsere zu testende Software abschicken. Dies ist jedoch auf den ersten Blick für einen Nutzer nicht ersichtlich. Zu Demonstrationszwecken beziehungsweise Testzwecken haben wir dazu einen zustandsändernden GET-Request verwendet.
Wir testen sowohl einen Cross-Origin- als auch einen Same-Site-Fall.
Die erste Website hat eine von der zu testenden Seite unterschiedliche Domain. Die zweite Website hat eine Subdomain unserer zu testenden Seite als URL. Diese Seite ist oben abgebildet. Sie ist, wie man sieht, für den Test sehr minimal gehalten und enthält im Wesentlichen nur den bösartigen Link. Wenn Playwright im Test auf den Link klickt, überprüfen wir jeweils, dass eine Fehlermeldung beim Aufruf des Links auf unsere zu testende Software erscheint. Zusätzlich überwachen wir mittels der route-Methode von Playwright den Endpunkt, der durch die bösartigen Aufrufe, also hier das Klicken auf den Link, angegriffen wird.
Um einen solchen Angriff zu verhindern, werden zum Beispiel CSRF-Cookies verwendet. Auf diese Weise wird verhindert, dass der Endpunkt den bösartigen Request beantwortet, da die bösartige Seite keinen Zugriff auf die CSRF-Cookies hat, die für einen erfolgreichen Request mitgeschickt werden müssen. Es wird in unserer Software bei einem versuchten CSRF-Angriff ein http-403-Fehlercode zurückgegeben. Dies überprüfen wir mit der oben dargestellten Methode.
Schlussbetrachtung
Wir haben hier an einigen Beispielen dargelegt, wie sich Sicherheitsaspekte für Webanwendungen, unter anderem CSP oder CSRF, im Zusammenspiel mit Playwright durch Ende-zu-Ende-Tests automatisiert testen lassen. Es wurde prinzipiell gezeigt, wie sich einige unterschiedliche Aspekte, zum Beispiel das Vorhandensein der erwarteten CSP in der http-Antwort, testen lassen. Die Tests lassen sich an unterschiedliche Webanwendungen anpassen und können auf diese Weise projektübergreifend eingesetzt werden. Die dargestellten Tests sind nur ein kleiner Ausschnitt von möglichen automatisierbaren Sicherheitstests. Weitere Sicherheitsaspekte, wie beispielsweise Zugriffsberechtigungen oder Brute-Force-Angriffe, können auch mithilfe von Ende-zu-Ende-Tests durch Playwright automatisiert getestet werden.
]]>adrianWeberUsing OpenRewrite for large-scale refactoring2025-10-23T00:00:00+00:002025-10-23T00:00:00+00:00https://blog.cronn.de/en/java/2025/10/23/openrewrite-for-refactoringOur Starting Position
What makes OpenRewrite so compelling is its automated nature. Migrating your code base between Java versions or upgrading a framework becomes a more relaxed task: You add the corresponding so-called “recipe”, execute rewriteRun, verify the code with your automated tests and then you’re done. Instead of replacing imports by hand or fighting with Gradle because of a rogue transitive dependency, you can take a coffee break while OpenRewrite works in the background.
An OpenRewrite recipe contains the logic to do a specific task, like changing org.junit imports with org.assertj equivalents. Due to the large user base and the open-source nature of most recipes, you can find recipes for everything from Spring Boot upgrades to switching from JUnit to AssertJ in minutes. In some cases, it might also be useful for enforcing code standards – much like an auto-formatter – where OpenRewrite can be integrated into the normal development pipeline, for example as a pre-commit hook.
How Does It Work?
There are “declarative” and “imperative” recipes which have different purposes. You can imagine declarative recipes like Lego. They are defined in a simple YAML file and typically consist of a list of existing recipes that should be executed together. Many of these recipes are available in OpenRewrite’s public repositories1 and are designed for common tasks, such as dependency upgrades or framework migrations. For example, the AssertJ2 recipe I mentioned earlier shows how an entire framework change can be automated with just a single declarative recipe.
Imperative recipes, on the other hand, are implemented in code. They define the actual logic that transforms your source code; in many cases by replacing old methods with new ones or changing an import. While there are many of these already available, OpenRewrite also provides a comprehensive Java API for writing your own recipes which we’ll explore in more detail next.
Lossless Semantic Tree and Visitor Pattern
OpenRewrite builds a Lossless Semantic Tree or LST3 when it is invoked. An LST, as its name suggests, is a much more detailed version of an AST (Abstract Syntax Tree). While the AST only contains the information necessary for evaluating the logical structure of the program, the LST includes whitespace information as well as a complete representation of the type relations. This means that once OpenRewrite has parsed a source file into an LST it can generate an exact replica from that LST alone. Because of this, local design abnormalities like an unusual indentation will be preserved as OpenRewrite doesn’t assume anything about your code styles. Additionally, because of the extensive type information, it can correctly identify the type of any given field. This is incredibly helpful if a recipe only wants to act on a very specific set of statements, for example for fixing a known vulnerability in a specific method from a package. OpenRewrite also uses this to verify that the new code uses existing types and doesn’t reference unavailable classes.
Once that LST is built, we get a chance to modify it. OpenRewrite is designed around the visitor pattern4 which allows us to define the behavior of a “visitor” which is moving along the LST. Different visitor types exist to balance how much you’re able to change vs. what can be validated by OpenRewrite. For example, a JavaIsoVisitor isn’t allowed to replace a method declaration with a field, however this is possible when using a JavaVisitor. We would do this by overriding visitX methods for all kinds of elements of a source file, such as class declarations, method declarations/invocations or conditionals. In each of these methods, we get some representation of that LST node in our code. These are immutable objects which contain the information present in the source file. We can use these when we want to change something for the current element, such as only renaming methods that start with “test”:
@OverridepublicJ.MethodDeclarationvisitMethodDeclaration(J.MethodDeclarationmethod,ExecutionContextexecutionContext){if(method.getSimpleName().startsWith("test")){// TODO: Rename this method}returnsuper.visitMethodDeclaration(method,executionContext);}
To allow for more control about how the LST is traversed , OpenRewrite leaves it up to us to decide if and where we call super.visitX. OpenRewrite generally recommends starting any visitX method with the call to super. Omitting this call entirely will mean that the sub-tree is not traversed at all. This can be beneficial for improving performance; however, it isn’t needed in most cases.
To further expand upon our example from above, let’s now change the method name. In OpenRewrite, the LST itself should not be mutated. Instead, we build a new “method object” that we then return from our method.
OpenRewrite detects that we returned an object different to what was passed into the method. It concludes that we must have changed something about the code and will store this new object in place of the old node in the LST. If you want to instead completely remove a statement, simply return null. In cases where you don’t want to do anything you should return super.visitX.
After the first visitor has traversed the whole LST, OpenRewrite will run another visitor through our recipe. If it detects any further changes, it will repeat this step, until no changes are made anymore. To make sure that changes from our recipe did not cause a “regression” in another active recipe, it will then re-run all other recipes in a similar pattern. Once that finishes it can confidently assert that all recipes have applied their logic to every single piece of code in the code base and every possible change has been made.
Lessons learned
Because of the inherent complexity in this type of meta programming, a test-driven development approach is highly favorable. It allows you to effectively cover the many possible edge cases.
Something that OpenRewrite already warns about in their documentation is recipe state. Recipe state increases the risk of artifacts from previous data unexpectedly changing the behaviour of your recipe. This not only introduces bugs that are difficult to find and fix, it also massively increases the complexity of your recipe. In our above example this can’t be avoided entirely, since we not only need to rename method declarations but also adjust any calls to those methods. This means we need to pass the information about our new names to visitMethodInvocation so that we can adjust the method calls accordingly.
The first option we have is the cursor. While the Java API of OpenRewrite itself doesn’t expose explicit methods like enterClass and exitClass, the cursor keeps track of where exactly we currently are in a stack-like structure, hence the name. It is cleared between every single cycle of a recipe and is best suited for communicating between two methods inside a visitor that come after each other. This wouldn’t be suitable for our scenario since a method call may come from a completely different place in the code base. Another possible solution is to put our information into the execution context. It is only ever cleared after all recipes have run so it is a much more persistent storage location. There are some limitations that you need to keep track of, however. The execution context does not allow mutating stored data to avoid hard to debug problems that occur due to state conflicts. You also need make sure that you don’t overwrite data from other recipes. The optimal way would be a ScanningRecipe5 visitor, where we first get the opportunity to scan the whole code base and collect information, after which a second visitor can apply changes.
Final Thoughts
With an extensive collection of open-source recipes and a fleshed-out Java API, OpenRewrite is a great way to approach code refactoring at a large scale. While the in-memory nature of the LST naturally will become a bottleneck for bigger projects, this problem is solved by Moderne’s custom solution with which it is possible to split the tree generation and store it more permanently.
While OpenRewrite is primarily focused on Java and the surrounding ecosystem, it also offers recipes for YAML, XML, JSON and even a few other languages like C# or Scala (although in a much more limited capacity).
Further code examples can be found in the cronn github6
]]>jakobRothPerformance-Testing mit k6: Ein Erfahrungsbericht2025-07-18T00:00:00+00:002025-07-18T00:00:00+00:00https://blog.cronn.de/de/testing/2025/07/18/performance-testing-mit-k6Projektkontext
GA-Lotse (Gesundheitsamt-Lotse) ist eine modular aufgebaute Webanwendung für Gesundheitsämter, die die interne Dokumentation und externe Kommunikation mit Bürgerinnen und Bürgern vereinfachen soll. Verschiedene Abteilungen eines Gesundheitsamtes sind in Modulen abgebildet, die für Gesundheitsämter konfiguriert werden können. Damit die Anwendung höchsten Sicherheitsstandards genügt, werden die Daten für jedes Modul separat gespeichert. Dies und weitere Sicherheitsfeatures wie das Zero-Trust-Prinzip führen zu intrinsischen Einbußen der Performance, weshalb das Testen der Performance ein wichtiger Teil des Projektes war.
Auswahl des Lasttesttools
Wie so häufig muss man nicht alles selbst implementieren, daher haben wir uns nach einem Tool umgesehen, das Performance-Testing unterstützt. Da wir eine Webanwendung testen wollen, sollte es Browsertests ermöglichen. Zudem waren unsere Hauptanforderungen folgende:
Die Möglichkeit den Testcode in TypeScript zu schreiben, da wir TypeScript auch für das Frontend der Anwendung und die Ende-zu-Ende-Tests verwenden
Open-Source-Verfügbarkeit des Tools
Ausführbarkeit auf einem selbstgehosteten Server (keine reine Cloud-Lösung)
Ein gutes Reporting, um die Ergebnisse der Tests für uns und die Entwickler zu visualisieren.
Nach der Evaluation mehrerer Tools haben wir uns für k6 entschieden. k6 unterstützt Browsertests, ermöglicht die Entwicklung in TypeScript und bietet in Kombination mit Grafana sowie durch individuell definierbare Metriken ein umfassendes Reporting.
Unser Setup
k6 führt die Performance-Tests aus und erzeugt dabei bereits einige Metriken, wie z.B. TTFB oder die Dauer der einzelnen Requests. Um diese und weitere Testergebnisse persistieren und visualisieren zu können, benötigten wir noch weitere Tools.
Als Datenbank haben wir uns für InfluxDB entschieden, da diese dafür optimiert ist, Daten zeitaufgelöst zu speichern. Zur Visualisierung der Ergebnisse haben wir Grafana-Dashboards genutzt, unter anderem da k6 zu Grafana gehört und es eine Schnittstelle zur InfluxDB bietet. Zur Abfrage der Daten aus der InfluxDB haben wir die proprietäre Datenbankabfragesprache Flux genutzt. Diese wird jedoch vermutlich in der nächsten Major-Version v3 nicht mehr oder nur noch eingeschränkt unterstützt.
Wir haben uns entschieden, die Tools lokal zu nutzen und sie in Docker-Container zu verpacken, um die Tests hardwareunabhängig ausführen zu können und nicht von Cloud-Anbietern abhängig zu sein. Alternativ besteht die Möglichkeit, Grafana Cloud k6 zu verwenden, um die lokale Installation der Tools zu vermeiden.
Performance-Tests mit k6
Ein Test mit k6 lässt sich mit einem Javascript oder TypeScript-File ausführen (s. Beispielskript).
In diesem Skript werden Optionen für den Test sowie die auszuführenden Testfunktionen definiert. Die Optionen werden als JSON definiert. Eine wichtige Option, die den Testverlauf bestimmt, ist scenarios. Dort können Szenarien definiert werden, die ausgeführt werden und somit den eigentlichen Test abbilden.
Für ein solches Szenario wird eine auszuführende Funktion, sowie die Anzahl an ausführenden parallelen Nutzern, die in k6 Virtual User (VU) genannt werden, definiert. Mit der Angabe von Zeiträumen kann die Gesamtdauer des Szenarios bestimmt werden. Außerdem können Rampen definiert werden, um die Anzahl der parallelen User während des Tests zu erhöhen oder zu verringern. Eine andere Möglichkeit den Testverlauf zu beeinflussen, ist, ein Zeitintervall festzulegen, in dem eine konkrete Anzahl an VUs das Szenario durchlaufen sollen.
Für einen Test können mehrere solcher Szenarien definiert werden, die mit unterschiedlichen Konfigurationen durchlaufen werden. Um diese Definition der Szenarien einfacher und schneller zu gestalten als ein langes JSON-File zu editieren, haben wir einen Builder entwickelt, der die Szenario-Konfiguration dynamisch erstellt und diesen auf GitHub zur Verfügung gestellt: https://github.com/cronn/k6-scenario-builder.
Unsere Erkenntnisse
Während des Testens sind uns einige Dinge aufgefallen, die es aus unserer Sicht zu berücksichtigen gilt. Zunächst ist es sinnvoll, eine dedizierte Maschine zur Verfügung zu haben, die die Tests ausführt. Da die Performance nicht nur durch Last vieler gleichzeitiger User beeinträchtigt wird, sondern auch von der Menge der Daten in der Datenbank, haben wir neben kurzen Spike-Tests auch Testszenarien erstellt, die eine Laufzeit über mehrere Stunden haben, um so die Datenmenge stetig zu erhöhen und eine Art Zeitraffer der tatsächlichen Nutzung der Anwendung zu simulieren. Diese Tests sind von einer externen Maschine deutlich komfortabler auszuführen als von dem eigenen Laptop.
Zudem benötigt die Ausführung eines Tests ausreichend Ressourcen auf der ausführenden Maschine. Daher sollte darauf geachtet werden, dass während der Ausführung eines Tests stets noch freie Ressourcen vorhanden sind, um nicht die Ergebnisse ungewollt zu beeinflussen. Dies haben wir bei der Ausführung von Browsertests mit einigen VUs bemerkt. Eine zu große Anzahl an gleichzeitig geöffneten Browsern hat die auszuführende Maschine zum Bottleneck gemacht. Unsere Lösung dafür ist, neben Browsertests gleichzeitig Szenarien zu definieren, die eine möglichst gleiche User-Journey abbilden, jedoch die nötigen Requests direkt ans Backend schicken, um somit die Last aufs Backend browserunabhängig zu erhöhen. Solche API-Szenarien eignen sich auch gut, um schnell ein Szenario zusammenzubauen und somit browserunabhängig einen Überblick über die Performance des Backends zu bekommen.
Eine weitere Erkenntnis von uns war, auf einer möglichst produktionsnahen Umgebung zu testen. Denn auch die Konfiguration einer Umgebung, gerade ein komplexer Microservice-Cluster, kann die Performance erheblich beeinflussen. Neben dem Ausführen der Tests von einer anderen Maschine und dem Testen auf einer produktionsähnlichen Umgebung war es für uns dennoch wichtig, auch das Testen vollständig auf dem eigenen Laptop zu ermöglichen. Dies ermöglicht die unabhängige Entwicklung neuer Szenarien durch die Entwickler und einen einfachen Zugang zu Datenbanken und Logs.
Es ist vorgekommen, dass wir durch die Konfiguration unserer Szenarios, vor allem bei langen Tests, fachliche Limits überschritten haben. Zum Beispiel haben wir unrealistisch viele Termine für einen Tag oder User angelegt, oder sogar zu viele User mit den gleichen Berechtigungen gehabt. Viele Größen können die Performance beeinflussen und sollten deshalb möglichst frühzeitig abgesteckt werden. Dadurch können wenig aussagekräftige Testläufe vermieden werden. Trotzdem war es uns auch wichtig, die bekannten Limits bewusst zu überschreiten, um die Reaktion der Anwendung zu testen und dort dann gegebenenfalls nachzubessern. Denn es ist ja nicht gesagt, dass der Kunde seine fachlichen Limits kennt oder diese durch technische Fehler nicht überschritten werden. Bei einem Termin zu viel sollte die Anwendung nicht unbedienbar werden. Ein Learning war für uns daher, fachliche Limits früh abzuklären und in den Tests zu beachten.
Vor- und Nachteile von k6
Während des Testens mit k6 sind wir immer mal wieder auf Probleme gestoßen. Eine erhebliche Einschränkung beim Entwickeln von Performance-Tests mit k6 ist ein fehlender Debugger. k6 nutzt eine eigene JavaScript-Engine, um den Testcode auszuführen, für die es keinen Debugger gibt. Die Javascript-Engine hat auch weitere Schwächen, denen man sich bewusst sein sollte. Beispielsweise unterstützt sie die verbreitete Fetch API nicht. Im Zusammenhang mit Browsertests sind Schwächen von k6, dass Methoden wie goto(), die darauf warten sollen, dass eine Seite geladen ist, im Zusammenspiel mit Chromium nicht immer zuverlässig funktionieren, was hin und wieder zu Timing-Problemen führt. Darüber hinaus müssen Locator über XPaths identifiziert werden, was sehr regressionsanfällig ist, sowie häufig unschön und lang. Zuletzt ist auch die Dokumentation von k6 häufig relativ knapp.
Einige andere Dinge haben sich als Vorteile von k6 herausgestellt. Das Reporting im Zusammenspiel mit der InfluxDB und Grafana hat wie erhofft sehr gut funktioniert. Über dieses Setup lassen sich ohne große Vorkenntnisse schnell aussagekräftige Plots erstellen und in einem Dashboard anzeigen, sodass die Testergebnisse analysiert und kommuniziert werden können. Außerdem funktioniert das parallele Ausführen von verschiedenen Szenarien, die jeweils ebenfalls mit parallelen virtuellen Usern ausgeführt werden, sehr gut. Dadurch lassen sich komplexe Szenarien erstellen, die verschiedene Arten von Performance-Tests wie Load-Tests, Spike-Tests und Soak-Tests abbilden. Dass die Testoptionen und insbesondere die Szenarien als JSON beschrieben werden ist sehr angenehm, da es einen fließenden Übergang zum Typescript-Code bietet. Außerdem hat man die Möglichkeit, die Browsertests in einem Headful Mode laufen zu lassen, sodass sich Probleme während der Ausführung erkennen lassen und behoben werden können.
Zusammenfassung
Da wir während der Testphase unsere Tests und unser Setup stetig weiterentwickelt haben, hat sich für uns ein iterativer Ansatz ausgezahlt. Wir sind mit zwei einfachen Szenarien für Module gestartet, die zu den wichtigsten in der Anwendung gehören. Bei diesen ersten Szenarien haben wir festgestellt, dass wir weitere Metriken und Plots in unseren Reports benötigen, um die Ergebnisse analysieren zu können. Iterativ haben wir dann Metriken zu unseren Tests hinzugefügt und im Grafana-Board visualisiert. Dies waren Informationen wie die Dauer von Requests, die Ladezeiten von bestimmten Seiten oder auch die CPU- und RAM-Auslastung der ausführenden Maschine. Für uns war vor allem die Dauer einzelner Requests von Bedeutung, welche Informationen relevant sind, hängt jedoch von der Anwendung ab. Durch in k6 eingebaute Metrik-Typen lässt sich die Erhebung von Informationen flexibel gestalten.
Die Arbeit mit k6 hat uns sowohl Stärken als auch Schwächen des Tools gezeigt. Ob k6 passend ist, hängt sicher vom Anwendungsfall ab, für uns war es aber trotz einiger signifikanter Schwächen ein passendes Tool.
]]>simonBiwerPerformance Testing with k6: A Field Report2025-07-18T00:00:00+00:002025-07-18T00:00:00+00:00https://blog.cronn.de/en/testing/2025/07/18/performance-testing-with-k6Project context
GA-Lotse is a modular web application for health authorities which is intended to simplify internal documentation and external communication with citizens. Different departments are mapped in modules, which then can be configured by the health authorities. To ensure that the application meets highest security standards, the data is stored separately for each module. This and other security features – such as the Zero Trust principle – lead to intrinsic performance losses, which is why performance testing was an important part of the project.
Selecting the load testing tool
It is often the case that you don’t have to implement everything yourself, so we looked for a tool which supports performance testing. Since we want to test a web application, the tool must allow browser testing. Our additional requirements were as follows:
The ability to write the test code in TypeScript, as we also use TypeScript for the frontend of the application and the end-to-end tests
Open-source availability of the tool
Executability on a self-hosted server (not a pure cloud solution)
Good reporting to visualize the results of the tests for us and the developers.
After evaluating several tools, we decided on k6. k6 supports browser tests, enables development in TypeScript and, in combination with Grafana and through individually definable metrics, offers comprehensive reporting.
Our setup
k6 runs the performance tests and generates some metrics, such as TTFB or the duration of the individual requests. However, in order to visualize these and other test results, we needed even more tools. We chose InfluxDB as the database, as it is optimized for storing data in a time-resolved manner. To visualize the results, we used Grafana-Dashboards because k6 belongs to Grafana and it provides an interface to InfluxDB. To query the data from the InfluxDB, we used the proprietary database query language Flux. However, this is not a long-term solution as Flux will probably no longer be supported – or only supported to a limited extent – in the next major version. We decided to use the tools locally and package them in Docker containers in order to be able to run the tests hardware-independently and not be dependent on cloud providers. Alternatively, there is the option of using Grafana Cloud k6
to avoid installing the tools locally.
Performance testing with k6
A test with k6 can be executed with a Javascript or TypeScript file (see example script).
This script defines options for the test and the test functions to be executed. The options are defined as JSON. An important option which determines the course of the test is scenarios. This is where executable scenarios can be defined, thus mapping the actual test.
To define a scenario one must define a function to be executed, as well as the number of executing parallel users, which in k6 are called Virtual Users (VU). The total duration of the scenario can be determined by specifying time periods. In addition, ramps can be defined to increase or decrease the number of parallel users during the test. Another way to influence the course of the test is to set a time interval in which a specific number of VUs should go through the scenario.
Several such scenarios can be defined for a test, which are then run using different configurations. To make this definition of the scenarios easier and faster than editing a long JSON file, we have developed a builder that dynamically creates the scenario configuration and makes it available on GitHub: https://github.com/cronn/k6-scenario-builder.
Our findings
During testing, we noticed a few things which need to be taken into account. First of all, it makes sense to have a dedicated machine available to run the tests. Since performance is not only affected by the load of many simultaneous users, but also by the amount of data in the database, we created both short spike tests as well as test scenarios that have a runtime of several hours in order to constantly increase the amount of data and simulate a kind of time-lapse of the actual use of the application. These tests can be carried out much more comfortably by an external machine than on your own laptop.
In addition, the execution of a test requires sufficient resources on the executing machine. Therefore, care should be taken to ensure that there are always free resources available during the execution of a test so as not to unintentionally influence the results. We noticed this when running browser tests with some VUs. Too many browsers open at the same time turned the machine into a bottleneck. Our solution to this is to define both scenarios and browser tests which depict the same user journey, but send the necessary requests directly to the backend in order to increase the load on the backend without accessing the browser. Such API scenarios are also well suited to quickly assemble a scenario and thus get an overview of the backend’s performance.
Another insight we gained was to test in an environment which was as close to production as possible. After all, the configuration of an environment, especially a complex microservice cluster, can have significant impact on performance. In addition to running the tests from another machine and testing on a production-like environment, it was still important for us to enable testing entirely on our own laptop. This allows developers to independently develop new scenarios and provide easy access to databases and logs.
It also occurred that we had exceeded professional limits by configuring our scenarios, especially during long tests. For example, we created an unrealistic number of appointments for one day or user, or even had too many users with the same permissions. Many different parameters can influence performance and should therefore be defined as early as possible, allowing us to avoid unnecessary test runs. Nevertheless, it was also important for us to deliberately exceed the known limits to test the limits of the application and then improve it where necessary. After all, the customer may not know their professional limits, or their limits might be reached through technical errors. The application should not become unusable because the user booked one appointment too many. One lesson learned was therefore to clarify professional limits at an early stage and to observe them in the tests.
Pros and Cons of k6
We ran into problems from time to time during testing with k6. A significant limitation of developing performance tests with k6 is a lack of a debugger. k6 uses its own JavaScript engine
to execute the test code, and there is no built-in debugger. The Javascript engine also has other weaknesses which you should be aware of, such as that it does not support the popular fetch API. In the context of browser tests, methods such as goto() are a weakness, as they do not always work reliably in combination with Chromium, which occasionally leads to timing problems. In addition, locators must be identified via XPaths, which is very susceptible to regression, as well as often unsightly and long. Finally, the documentation of k6 is often relatively short.
However, k6 also has many advantages. The reporting in combination with InfluxDB and Grafana works very well. Meaningful plots can be quickly created in such a setup without much prior knowledge and then be displayed in a dashboard so that the test results can be analyzed and communicated. In addition, the parallel execution of different scenarios, each of which is also executed with parallel virtual users, works very well. It allows you to create complex scenarios which map different types of performance tests, such as load tests, spike tests, and soak tests. The fact that the test options (and especially the scenarios) are described in JSON is an advantage as it provides a smooth transition to the Typescript code. You also have the option of running the browser tests in headful mode, so that problems can be detected and fixed during execution.
Summary
Since we had constantly developed both our tests and setup during the test phase, an iterative approach paid off for us. We started with two simple scenarios for application-critical modules. In these initial scenarios, we realized that we needed more metrics and plots in our reports to analyze the results. Iteratively, we then added metrics to our tests and visualized them in the Grafana board. These metrics included information such as the duration of requests, the loading times of certain pages, or even the CPU and RAM usage of the executing machine. The duration of individual requests was particularly important for us, but which information is relevant depends on the application. Metric types built into k6 allow the collection of information to be flexibly designed. Working with k6 has shown us both strengths and weaknesses of the tool. Whether k6 is the best choice certainly depends on the use case, but for us it was a suitable tool despite some significant weaknesses.
]]>simonBiwerAnalyse von Geschäftsberichten mit LLMs – Teil 22025-06-24T00:00:00+00:002025-06-24T00:00:00+00:00https://blog.cronn.de/de/ai/largelanguagemodels/2025/06/24/analyse-von-geschaeftsberichten-mit-llms-2Willkommen zurück zu unserer Serie über die Analyse von Geschäftsberichten mit KI! Im ersten Teil haben wir anhand eines Beispiels gezeigt, wie die Extraktion von Kennzahlen aus Geschäftsberichten mit LLMs wie ChatGPT grundsätzlich funktioniert. Jetzt gehen wir weiter in die Tiefe und zeigen dafür eine Lösung, die wir in Zusammenarbeit mit North Data produktiv einsetzen.
Wir konnten damals demonstrieren, wie sich relevante Informationen aus den dichten Textwüsten von Geschäftsberichten strukturiert herausfiltern lassen. Doch wer das in der Praxis skalieren will, stößt schnell an Grenzen – sei es bei der Genauigkeit über viele verschiedene Dokumente hinweg, der robusten Verarbeitung komplexer Layouts und Tabellen oder der Wirtschaftlichkeit, die für eine großflächige Analyse nötig ist.
Genau hier hat sich in der Zwischenzeit aber einiges getan. Mit Gemini Flash von Google steht ein Modell bereit, das die Karten für die automatisierte Dokumentenanalyse in Sachen Geschwindigkeit, Kontextverständnis und dem Ausliefern strukturierter Daten neu mischt.1 In diesem zweiten Teil wollen wir daher tief eintauchen: Was macht Gemini Flash so viel leistungsfähiger für diese spezifische Aufgabe als frühere Ansätze oder die klassischen OCR-Pipelines? Wie ermöglicht es den Schritt von der Machbarkeitsstudie zum produktiven Werkzeug? Werfen wir einen Blick unter die Haube.
Gemini extrahiert strukturierten JSON-Code aus PDFs.
Der klassische Ansatz: OCR als Basis, aber nicht die ganze Lösung
Bevor wir uns den Fähigkeiten von Gemini widmen, lohnt sich ein kurzer Blick auf den traditionellen Weg zur Datenextraktion aus PDFs. Dieser beginnt fast immer mit Optical Character Recognition (OCR). OCR-Tools helfen uns, wenn es darum geht, Text aus gescannten Dokumenten oder reinen Bild-PDFs lesbar zu machen. Sie wandeln Pixel in Buchstaben um. Das Ergebnis ist nicht nur der „rohe“ Textinhalt, sondern oft auch dessen Position auf der Seite, meist in Form von Koordinaten oder sogenannten Bounding Boxes für jedes erkannte Wort oder jede Zeile.
Bounding Boxes bei OCR durch Azure Document Intelligence.
Nach diesem rohen Text samt Koordinaten fängt die eigentliche Arbeit oft erst an, denn für eine sinnvolle Analyse brauchen wir strukturierte Daten, keinen Fließtext. Hier beginnen die Herausforderungen:
Zuerst muss die Struktur im reinen Text-Output erkannt werden. Wie identifiziert man automatisch Tabellen, zusammengehörige Key-Value-Paare (wie „Umsatz: 10 Mio. €“) oder semantisch sinnvolle Blöcke? Dafür sind häufig komplexe, nachgelagerte Schritte notwendig – seien es speziell entwickelte Parser, regelbasierte Systeme, die auf bestimmte Muster achten, oder sogar separate Machine-Learning-Modelle, die auf Aufgaben wie Tabellenerkennung trainiert wurden.
Diese nachgelagerten Systeme sind allerdings oft anfällig für Layout-Änderungen. Kleine Anpassungen im Design eines Berichts von einem Jahr zum nächsten, oder die unterschiedlichen Formate verschiedener Unternehmen, können mühsam erstellte Regeln oder Parser aus dem Tritt bringen und unbrauchbar machen.
Hinzu kommt das fehlende Kontextverständnis. OCR liefert zwar den Text, versteht aber dessen Bedeutung nicht. Zu erkennen, dass sich der Begriff „Total Assets“ auf Seite 10 auf dieselbe Kennzahl bezieht wie eine detaillierte Aufschlüsselung in einer Tabelle auf Seite 45, übersteigt die Fähigkeiten reiner Texterkennung.
All diese Faktoren führen zu Komplexität und somit zu einem hohen Entwicklungs- und Wartungsaufwand. Es lässt sich feststellen: OCR ist ein wichtiges Werkzeug im Kasten. Aber für das Ziel der End-to-End-Extraktion strukturierter Daten ist es meist nur der erste Schritt in einer komplexen und oft fragilen Verarbeitungskette.
Unser Weg zum Produktiveinsatz: Evaluation, Modellwahl und Integration
Der Sprung von einer erfolgreichen Demonstration (wie in Teil 1 gezeigt2) zu einem zuverlässigen, skalierbaren Produktivsystem erforderte einen systematischen Ansatz und Weiterentwicklungen in mehreren Bereichen.
Zunächst war eine solide Evaluation unerlässlich. Wir haben also manuell einen Datensatz aus 100 repräsentativen englischen Geschäftsberichten kuratiert. Für die wichtigsten Kennzahlen wurden die korrekten Werte (Ground Truth) von Hand annotiert und in einer Tabelle gesammelt. Nur mit einer solchen verlässlichen Basis lässt sich die Qualität verschiedener Modelle und Ansätze objektiv messen und über die Zeit verfolgen.
Parallel dazu erweiterten wir den Umfang der Extraktion im Vergleich zur alten Lösung deutlich. Statt nur einiger weniger Kennzahlen war das Ziel nun, eine breite Palette von über 20 relevanten Werten pro Bericht zuverlässig zu extrahieren. Dazu gehören unter anderem die vom Unternehmen ausgewiesenen Lohnkosten, Angaben zu Gewinn und Verlust, Barmittel, aber auch Daten wie die durchschnittliche Mitarbeiterzahl oder der Name des Wirtschaftsprüfers.
Diese anspruchsvolleren Ziele führten uns zu Tests verschiedener Modelle. Die Wahl fiel schließlich auf Gemini 2.0 Flash Lite: Dieses Modell vereinte für unseren Anwendungsfall alle entscheidenden Faktoren optimal.
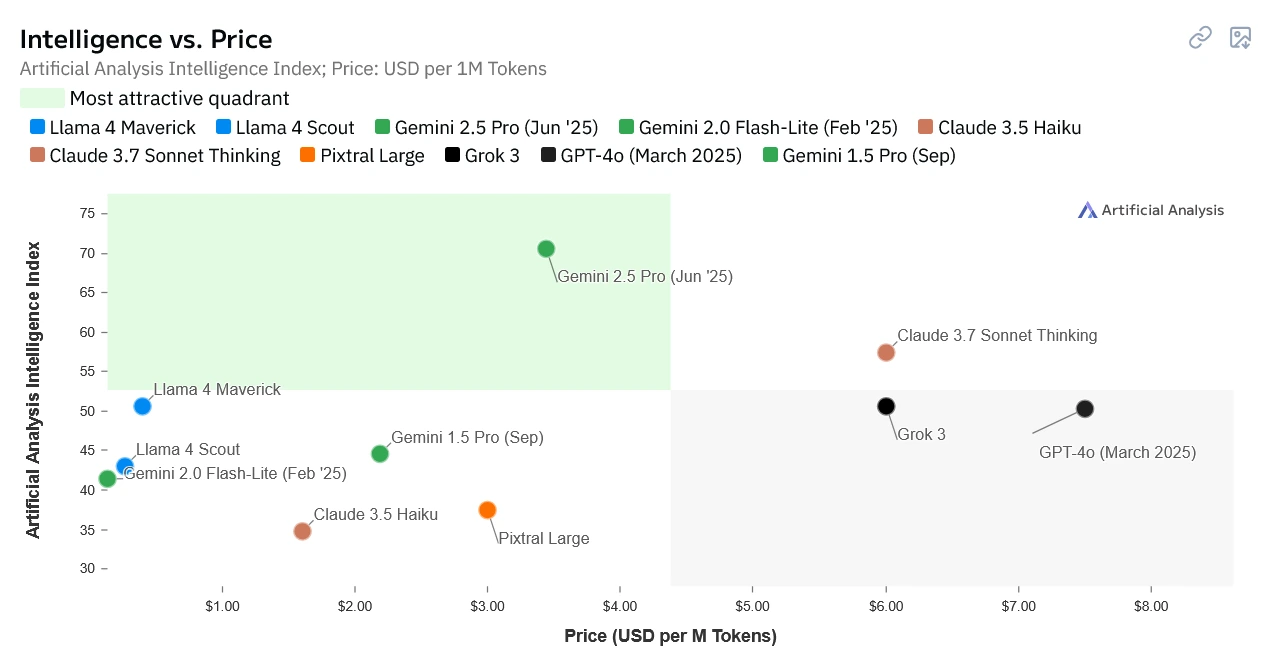
LLM-Vergleich anhand der Parameter „Intelligenz“ und „Preis“, via artificialanalysis.ai.
Qualität & Geschwindigkeit: In unseren Tests zeigte Gemini 2.0 Flash Lite eine überraschend hohe Genauigkeit für die meisten der anvisierten Kennzahlen, die oft mit der von größeren, teureren Modellen mithalten konnte. Google selbst positioniert die Flash-Modelle als optimiert für Aufgaben, bei denen es auf hohe Geschwindigkeit und Effizienz bei gleichzeitig guter Qualität ankommt3. Unsere Erfahrungen bestätigen, dass das Modell seinem „Flash“ im Namen in puncto Verarbeitungsgeschwindigkeit gerecht wird.
Kosten: Ein entscheidender Faktor für den Einsatz im großen Maßstab sind die Kosten. Gemini 2.0 Flash Lite ist deutlich günstiger als die größeren Pro-Modelle. Im Vergleich zu älteren Modellen wie gpt-3.5-turbo-16k aus dem ersten Teil, das im Juli 2023 noch etwa 3 US-Dollar pro Million Input-Token kostete4, ist die von uns genutzte Gemini-Flash-Variante um den Faktor 40 günstiger5! Das macht die Verarbeitung tausender Berichte wirtschaftlich tragbar.
Multimodalität & Kontext: Ein wesentlicher Vorteil gegenüber reinen Textmodellen oder klassischen OCR-Pipelines ist die Multimodalität von Gemini. Vereinfacht gesagt bedeutet das: Statt nur den rohen Text und dessen Koordinaten zu liefern (wie traditionelle OCR), kann Gemini Flash gleichzeitig den Text „lesen“ und das Seitenlayout „sehen“. Es „versteht“, wie Text in Spalten oder Tabellen angeordnet ist, erkennt Überschriften und kann Bilder oder Diagramme im Dokument interpretieren. Dadurch erfasst es den Kontext, den die reine Textreihenfolge oft nicht vermittelt, wesentlich besser. Dies ist gerade bei den komplexen und variantenreichen Layouts von Geschäftsberichten ein großer Vorteil. Gepaart mit dem langen Kontextfenster, das die Analyse umfangreicher Dokumentabschnitte am Stück erlaubt, ist dies ein entscheidender Fortschritt.
Diese Kombination aus guter Qualität, hoher Geschwindigkeit, niedrigen Kosten und der Fähigkeit, Dokumente ganzheitlich zu verstehen, machte Gemini 2.0 Flash Lite zur guten Wahl für unseren produktiven Einsatz in Zusammenarbeit mit North Data.
Gemini Flash in Aktion: Der Workflow mit Structured Outputs
Der Kern unseres Ansatzes kombiniert die Stärken von Gemini mit pragmatischen Lösungen, um auch mit den Eigenheiten sehr umfangreicher Dokumente umzugehen.
Ein zentrales Problem stellen lange Geschäftsberichte dar, die oft hunderte von Seiten umfassen. Das gesamte Dokument an Gemini zu übergeben, wäre zwar ideal für den Kontext, ist aber zu teuer für den Masseneinsatz. Um dieses Problem zu umgehen, haben wir einen mehrstufigen Ansatz entwickelt: Zuerst setzen wir nach wie vor auf bewährte OCR-Technologie, um den reinen Text des gesamten Dokuments zu extrahieren. Dieser Rohtext dient uns dann als Basis für eine schnelle Voranalyse mittels Schlüsselwörtern. Wir suchen nach Begriffen und Phrasen, die typischerweise auf relevante Abschnitte hindeuten, wie zum Beispiel „Consolidated Balance Sheet“, „Income Statement“ oder „Notes to the Financial Statements“.
Basierend auf dieser Analyse wählen wir die bis zu 100 Seiten aus, die am wahrscheinlichsten die gesuchten Finanzkennzahlen enthalten. Nur dieser Auszug des Berichts wird dann als PDF-Kontext an Gemini Flash Lite übergeben. Dieser Kniff reduziert nicht nur die Verarbeitungskosten erheblich, sondern hilft auch, das Modell auf die wirklich wichtigen Teile des Dokuments zu konzentrieren und das „Rauschen“ irrelevanter Seiten zu minimieren.
Nachdem wir die relevanten Seiten isoliert haben, beauftragen wir Gemini mit der gezielten Extraktion in ein vordefiniertes Format. Ein weiterer Baustein für präzise Ergebnisse ist hierbei die Nutzung von sogenannten Structured Outputs. Gemini besitzt die Fähigkeit, nicht nur Text zu generieren, sondern direkt strukturierte JSON-Daten zu liefern, die einem vorgegebenen Schema folgen.
Wir definieren dazu im Vorfeld ein klares Zielschema, das genau festlegt, welche Datenfelder wir erwarten und in welchem Format (wie etwa „Zahl“, „Text“, „Währungssymbol“). In Python nutzen wir dafür gerne Pydantic zur einfachen Definition und Validierung. Diese Struktur geben wir dem Modell explizit als Anweisung mit. Das ist nicht nur praktisch für die automatisierte Weiterverarbeitung, sondern verbessert auch nachweislich die Qualität: In unseren Tests führte allein dieser Schritt zu einer Verbesserung des Evaluations-Ergebnisses um rund 4 %.
Hier ein vereinfachtes Python-Beispiel zur Illustration des Prinzips mit der google-genai -Bibliothek und Structured Outputs:
fromgoogleimportgenaifromgoogle.genaiimporttypesfrompydanticimportBaseModel,Fieldclient=genai.Client(api_key="GEMINI_API_KEY")# Define the desired output structure using Pydantic
classFinancialData(BaseModel):revenue:float|None=Field(description="Total revenue reported for the fiscal year.")net_income:float|None=Field(description="Net income or profit after tax.")total_assets:float|None=Field(description="Total assets value.")fiscal_year:int|None=Field(description="The ending year of the fiscal period.")currency_symbol:str|None=Field(description="Currency symbol used for major values (e.g., $, £, €).")# Upload the relevant PDF pages (assuming 'selected_report_pages.pdf' was created by pre-filtering)
pdf_file=client.files.upload(file="'selected_report_pages.pdf")prompt="""
Please analyze the provided pages from the annual report PDF.
Extract the following financial figures for the main consolidated entity reported:
- Total Revenue
- Net Income (Profit after tax)
- Total Assets
- The Fiscal Year End
- The primary Currency Symbol used for the main financial figures (£, $, € etc.)
Return the data strictly adhering to the provided 'FinancialData' schema.
If a value cannot be found or determined confidently, leave the corresponding field null.
Pay close attention to units (e.g., thousands, millions).
"""try:response=client.models.generate_content(model="gemini-2.0-flash-lite-001",contents=[prompt,pdf_file],config=types.GenerateContentConfig(response_mime_type="application/json",response_schema=FinancialData,),)extracted_data=FinancialData.model_validate_json(response.text)print(extracted_data)exceptExceptionase:print(f"\nAn error occurred: {e}")finally:client.files.delete(name=pdf_file.name)
Ein Blick auf die Zahlen: Wie gut funktioniert es wirklich?
Um die tatsächliche Leistung unseres Ansatzes mit Gemini Flash objektiv zu bewerten, haben wir, wie erwähnt, einen Datensatz aus 100 manuell annotierten Geschäftsberichten erstellt. Dieser dient als Ground Truth, gegen den wir die Extraktionsergebnisse des Modells prüfen.
Die Gesamtgenauigkeit über alle Kennzahlen und Berichte hinweg für unseren Ansatz lag bei 83,5 %. Dies waren die ersten Machbarkeitswerte für die Lösung, die wir bei North Data integriert haben. Das ist eine solide Basis und zeigt, dass der Ansatz grundsätzlich funktioniert. Interessanter wird es jedoch, wenn man sich die Genauigkeit für einzelne Kennzahlen ansieht:
Kennzahlen (Parameter)
Genauigkeit
Gesamt (Overall)
83.5%
capital
96.0%
cash
95.0%
employees
95.0%
revenue
95.0%
equity
98.0%
currencySymbol
99.0%
auditorName
89.0%
materials
89.0%
…
…
liabilities (creditors)
75.0%
currentAssets
64.0%
realEstate
60.0%
receivables
52.0%
tax
41.0%
Was verrät uns diese Tabelle und wo liegen die aktuellen Hürden?
Die Evaluationsergebnisse zeichnen ein klares Bild: Bei klar definierten Stammdaten oder Werten, die in Geschäftsberichten oft prominent und relativ einheitlich ausgewiesen werden, erzielt das Modell sehr hohe Genauigkeitswerte. Dazu zählen beispielsweise capital (Eigenkapital), equity (Reinvermögen), die employees (Anzahl der Mitarbeiter), cash (Barmittel) oder das currencySymbol (Währungssymbol). Erfreulicherweise sind Halluzinationen – also das Erfinden von Zahlen, die im Dokument nicht existieren – in unseren Tests kein signifikantes Problem gewesen. Wenn Fehler auftraten, dann meist durch Fehlinterpretationen vorhandener Zahlen, nicht durch deren freie Erfindung.
Schwieriger wird es für das Modell bei komplexeren Kennzahlen. Hier zeigen sich die Grenzen des aktuellen Ansatzes, insbesondere wenn es um semantische Unschärfe und variierende Detailgrade geht. Viele Bilanzposten können in Berichten unterschiedlich definiert, benannt oder aufgeschlüsselt sein. Begriffe wie „Total Assets“ sind nicht immer absolut eindeutig – meint es die Bilanzsumme vor oder nach Abzug bestimmter Posten wie Goodwill, also den immateriellen Firmenwert?
Die genaue Abgrenzung von currentAssets (kurzfristige Vermögenswerte), receivables (Forderungen) oder liabilities (Verbindlichkeiten) variiert zwischen Unternehmen und Berichtsstandards. Hier stößt das Modell manchmal an seine Grenzen, die exakte, im jeweiligen Bericht gültige Definition allein aus dem unmittelbaren Kontext zu erschließen.
Ebenso spielt die Abhängigkeit von Layouts und der Platzierung von Informationen eine Rolle. Einige Werte, wie beispielsweise realEstate (Immobilienvermögen), sind oft nicht prominent auf den Hauptseiten der Bilanz zu finden, sondern detailliert in den „Notes to the Financial Statements“ (Anhang) versteckt. Die Fähigkeit des Modells, solche Informationen über verschiedene Seiten und Layouts hinweg korrekt zuzuordnen, ist stark gefordert und führt zu niedrigeren Genauigkeitswerten.
Schließlich erfordern manche Kennzahlen komplexere Interpretationen oder implizite Berechnungen. Die Extraktion von Werten wie tax (Steuern) ist hierfür ein gutes Beispiel. Oft spielen verschiedene Steuerarten (Ertragssteuern, Umsatzsteuern etc.) und latente Steuern eine Rolle, die über mehrere Abschnitte verteilt sein können. Die korrekte Zusammenführung und Interpretation dieser Informationen sind anspruchsvoll, was die aktuelle Genauigkeit von nur 41 % für diese Kennzahl erklärt.
Diese quantitativen Ergebnisse bestätigen unsere qualitativen Beobachtungen: Das Modell ist hervorragend darin, klar benannte Informationen zu finden. Bei Mehrdeutigkeiten, stark variierenden oder komplexen Layouts und der Notwendigkeit, implizites Wissen oder Zusammenhänge über mehrere Textstellen hinweg zu verstehen, stößt es jedoch an Grenzen.
Ein weiterer wichtiger Aspekt ist die variierende Genauigkeit zwischen verschiedenen Unternehmen. Die Standardabweichung der Genauigkeit pro Unternehmen liegt bei etwa 9,2 %. Besonders auffällig ist, dass die Genauigkeit bei den sehr großen, oft hunderte Seiten umfassenden und individuell gestalteten Berichten von börsennotierten Unternehmen (PLCs) wie AstraZeneca (50 %), Barclays (65 %), HSBC (50 %), Shell (70 %) oder Unilever (55 %) teilweise deutlich abfällt.
Tests mit unterschiedlich langen Ausschnitten aus den Berichten zeigten, dass die Länge des zu bewältigenden Kontextes für Gemini keine größere Schwierigkeit darstellt. Wir gehen daher davon aus, dass vor allem die Einzigartigkeit der Berichtsstrukturen dieser Konzerne für das Modell herausfordernd sind. Während Gemini Flash Lite gut mit Layouts zurechtkommt, die oft von kleineren Unternehmen mit Standardsoftware erstellt werden, sind diese komplexen Fälle eine größere Hürde. Eine Erklärung könnte sein, dass es die vom Standard abweichenden Berichte seltener in Geminis Trainingsdaten geschafft haben.
Ein weiteres wiederkehrendes Problem ist die korrekte Erfassung von Einheiten und Skalierungen. Das Übersehen oder die Fehlinterpretation von Angaben wie „in Tausend £“ oder „Millions USD“ führt zu extrahierten Werten, die um Faktoren von 1.000 oder 1.000.000 falsch sind. Hier sind robuste nachgelagerte Validierungsregeln und gezieltes Prompting notwendig, um das Modell für diese Details zu sensibilisieren.
Auch die Darstellung negativer Zahlen, die in Geschäftsberichten oft durch Klammern erfolgt (z.B. „(1.234)“ statt „-1.234“), erfordert einen expliziten Hinweis im Prompt, damit das Modell diese Konvention korrekt interpretiert und die Zahlen mit dem richtigen Vorzeichen extrahiert. Wie bereits gesagt stellen Halluzinationen (im Gegensatz zu älteren Modellen) hier keine großen Probleme dar, bloß die Interpretation der Zahlen gelingt nicht immer.
Zu guter Letzt stehen wir auch vor dem klassischen Trade-off zwischen Kosten und Leistung bei besonders komplexen Fällen. Anspruchsvollere Reasoning-Ansätze wie Chain-of-Thought (CoT), bei denen das Modell seine „Gedankenschritte“ explizit macht, oder der Einsatz noch größerer und leistungsfähigerer Modelle (z.B. Gemini 2.5 Pro) könnten bei den genannten Problemen, insbesondere bei den komplexen Berichten, Abhilfe schaffen.
Diese sind jedoch aktuell oft noch deutlich teurer. So ist beispielsweise Gemini 2.5 Pro derzeit 16- bis 32-mal so teuer wie das von uns genutzte Gemini 2.0 Flash Lite. Auch das sehr gängige GPT-4.1, welches in ChatGPT zum Einsatz kommt, kostet mit 2 $ pro 1 Million Input Tokens ca. 27-mal so viel wie Gemini 2.0 Flash Lite. Die Verarbeitung eines durchschnittlichen Berichts aus unserem Testdatensatz mit 30 Seiten kostet mit unserer Lösung daher nur ca. 0,0007 $!
Fazit: Gemini Flash als leistungsstarke Ergänzung im Werkzeugkasten
Gemini Flash hat sich für uns als nützlicher Baustein erwiesen, um die Extraktion strukturierter Daten aus Geschäftsberichten auf ein neues Level zu heben und in den produktiven Einsatz bei North Data zu bringen. Es ersetzt nicht zwangsläufig die gesamte klassische Pipeline (wie unsere OCR-Vorfilterung zeigt), aber es bietet eine enorm leistungsfähige, integrierte Alternative für den Kernprozess der intelligenten Datenextraktion und -strukturierung.
Die Fähigkeit, Layouts zu verstehen, über einen größeren Kontext zu arbeiten und direkt strukturierte Outputs zu liefern, reduziert die Komplexität und den Wartungsaufwand im Vergleich zu traditionellen, mehrstufigen Ansätzen erheblich. Die Herausforderungen bleiben, aber der Fortschritt ist deutlich und eröffnet neue Möglichkeiten für die automatisierte Finanzdatenanalyse.
Wir sind gespannt, wie sich diese Technologie weiterentwickelt und welche neuen Lösungsansätze sich ergeben. Habt ihr ähnliche Erfahrungen gemacht oder andere Strategien entwickelt? Teilt eure Gedanken mit uns!
Dieser Blogpost wurde mit Unterstützung von Gemini-2.5-Pro geschrieben.
]]>leonardThieleAnalyzing Business Reports with LLMs – Part 22025-06-24T00:00:00+00:002025-06-24T00:00:00+00:00https://blog.cronn.de/en/ai/largelanguagemodels/2025/06/24/analyse-von-geschaeftsberichten-mit-llms-2-enWelcome back to our series on analysing annual reports with AI. In Part One we showed how the extraction of key figures from annual reports with LLMs (such as ChatGPT) works. Now we are going deeper and showing the final working solution, which we are using in cooperation with North Data.
We have already demonstrated how relevant information can be filtered out of the dense text of annual reports in a structured way. But if you want to scale this process in practice, you quickly reach its limits – be it in terms of accuracy across many different documents, the robust processing of complex layouts and tables, or the cost-effectiveness of large-scale analysis.
This is exactly where there have been many exciting developments. With Gemini Flash from Google, a model is available which reshuffles the cards for automated document analysis in terms of speed, contextual understanding, and the delivery of structured data.1 In this second part, we will ask: what makes Gemini Flash so more powerful for this specific task than previous approaches or the classic OCR pipelines? How does it make the step from feasibility study to productive tool? Let us look under the hood.
Gemini extracts structured JSON code from PDFs.
The classic approach: OCR as the basis, but not the whole solution
Before we dive into Gemini’s capabilities, it is worth looking at the traditional way of extracting data from PDFs. This most commonly starts with Optical Character Recognition (OCR). OCR tools generate text from scanned documents or image-only PDFs by converting pixels into letters. The result is not only the raw text content, but often also its position on the page, usually in the form of coordinates or so-called bounding boxes for each recognized word or line.
OCR Bounding Boxes from Azure Document Intelligence.
However, for a meaningful analysis we need structured data, not continuous text. This is where the challenges begin.
The first hurdle lays in the structure in the pure text output being recognized. How do you automatically identify tables, related key-value pairs (such as “revenue: €10 million”) or semantically meaningful blocks? This often requires complex, downstream steps – whether purpose-built parsers, rule-based systems that look for specific patterns, or even separate machine learning models trained on tasks such as table recognition.
However, these downstream systems are often susceptible to layout changes. Small adjustments in the design of a report from one year to the next or the format differing between companies can throw off painstakingly created rules or parsers and make them unusable.
In addition, there is a lack of contextual understanding. OCR provides the text but does not understand its meaning. Recognizing that the term “Total Assets” on page 10 refers to the same metric as a detailed breakdown in a table on page 45 is beyond the capabilities of pure text recognition.
All these factors create complexity and thus lead to a high development and maintenance effort. It can be said that OCR is a valuable tool, but for the extraction of structured data it is usually only the first step in a complex and often fragile processing chain.
Our path to productive use: evaluation, model selection and integration
The leap from successful demonstration (as shown in Part 12) to a reliable, scalable production system required a systematic approach and further developments in several areas.
Firstly, a solid evaluation was essential. To this end we manually curated a dataset of 100 representative English annual reports. For the most important key figures, the correct values (ground truth) were annotated by hand and collected in a table. Only with such a reliable basis can the quality of different models and approaches be objectively measured and tracked over time.
Secondly, we significantly expanded the scope of extraction. Instead of just a few key figures, the goal was now to reliably extract a wide range of over 20 relevant values per report. This includes, among other things, the wage costs, information on profit and loss, cash flow, but also data such as the average number of employees or the name of the auditor.
These more demanding goals led us to test different models. In the end, the choice fell on Gemini 2.0 Flash Lite: This model optimally combined all the decisive factors for our application.
LLM comparison based on the parameters "intelligence" and "price", via artificialanalysis.ai.
Quality & Speed: In our tests, Gemini 2.0 Flash Lite showed high accuracy for most of the targeted metrics, often keeping up with that of larger, more expensive models. Google itself positions the Flash models as optimized for tasks where it is important to maintain high speed and efficiency while maintaining high quality 3. Our experience confirms that the model lives up to its “flash” in its name in terms of processing speed.
Cost: A decisive factor for large-scale deployment is cost. Gemini 2.0 Flash Lite is significantly cheaper than the larger Pro models. Compared to older models like gpt-3.5-turbo-16k, which still cost about $3 per million input tokens in July 2023 4, the Gemini Flash variant we used is cheaper by a factor of 40 5! This makes the processing of thousands of reports economically viable.
Multimodality & Context: A significant advantage over plain text models or classic OCR pipelines is Gemini’s multimodality. Put simply, instead of just delivering the raw text and its coordinates (like traditional OCR), Gemini Flash can “read” the text and “see” the page layout at the same time. It “understands” how text is arranged in columns or tables, recognizes headings, and can interpret images or charts in the document. As a result, it is better at capturing context which the pure text order often does not convey. This is a great advantage, especially with the complex and varied layouts of annual reports. Coupled with the long context window, which allows the analysis of large document sections in one go, this is a decisive step forward.
This combination of good quality, high speed, low cost, and the ability to understand documents holistically made Gemini 2.0 Flash Lite a viable choice for our productive deployment in collaboration with North Data.
Gemini Flash in Action: The Workflow with Structured Outputs
The core of our approach combines the strengths of Gemini with pragmatic solutions to deal with the peculiarities of large documents.
A central problem with annual reports is that they often comprise hundreds of pages. While handing over the entire document to Gemini would be ideal for context, it is too expensive for mass use. To get around this problem, we have developed a multi-step approach: First, we still rely on proven OCR technology to extract the plain text of the entire document. This raw text then serves as the basis for a quick preliminary analysis using keywords. We look for terms and phrases that typically indicate relevant sections, such as “Consolidated Balance Sheet”, “Income Statement” or “Notes to the Financial Statements”.
Based on this analysis we then select the up to 100 pages that are most likely to contain the financial ratios we are looking for. Only this selection is then passed on to Gemini Flash Lite as a PDF context. This trick not only significantly reduces processing costs but also helps to focus the model on the important parts of the document and minimize the “noise” of irrelevant pages.
After isolating the relevant pages, we commission Gemini to extract them into a predefined format. Another building block for precise results is the use of so-called structured outputs. Gemini can not only generate text but also provides directly structured JSON data which follows a predetermined scheme.
To do this, we define a clear target scheme in advance, which in turn defines exactly which data fields we expect and in which format (such as “number”, “text”, “currency symbol”). In Python, we like to use Pydantic for easy definition and validation. We explicitly give this structure to the model as an instruction. This is not only practical for automated further processing, but also demonstrably improves quality: In our tests, this step alone led to an improvement in the evaluation result of around 4%.
Here is a simplified Python example to illustrate the principle with the google-genai library and structured outputs:
fromgoogleimportgenaifromgoogle.genaiimporttypesfrompydanticimportBaseModel,Fieldclient=genai.Client(api_key="GEMINI_API_KEY")# Define the desired output structure using Pydantic
classFinancialData(BaseModel):revenue:float|None=Field(description="Total revenue reported for the fiscal year.")net_income:float|None=Field(description="Net income or profit after tax.")total_assets:float|None=Field(description="Total assets value.")fiscal_year:int|None=Field(description="The ending year of the fiscal period.")currency_symbol:str|None=Field(description="Currency symbol used for major values (e.g., $, £, €).")# Upload the relevant PDF pages (assuming 'selected_report_pages.pdf' was created by pre-filtering)
pdf_file=client.files.upload(file="'selected_report_pages.pdf")prompt="""
Please analyze the provided pages from the annual report PDF.
Extract the following financial figures for the main consolidated entity reported:
- Total Revenue
- Net Income (Profit after tax)
- Total Assets
- The Fiscal Year End
- The primary Currency Symbol used for the main financial figures (£, $, € etc.)
Return the data strictly adhering to the provided 'FinancialData' schema.
If a value cannot be found or determined confidently, leave the corresponding field null.
Pay close attention to units (e.g., thousands, millions).
"""try:response=client.models.generate_content(model="gemini-2.0-flash-lite-001",contents=[prompt,pdf_file],config=types.GenerateContentConfig(response_mime_type="application/json",response_schema=FinancialData,),)extracted_data=FinancialData.model_validate_json(response.text)print(extracted_data)exceptExceptionase:print(f"\nAn error occurred: {e}")finally:client.files.delete(name=pdf_file.name)
A look at the numbers: How well does it really work?
To objectively assess the actual performance of our approach with Gemini Flash, we created a dataset of 100 manually annotated business reports. This serves as ground truth against which we check the extraction results of the model.
The overall accuracy across all metrics and reports for our approach was 83.5%. These were the first feasibility values for the solution we integrated at North Data. This is a solid basis which demonstrates that the approach works. However, it gets more interesting when you look at the accuracy for individual metrics:
Key figure (parameters)
Accuracy
Overall
83.5%
capital
96.0%
cash
95.0%
employees
95.0%
revenue
95.0%
equity
98.0%
currencySymbol
99.0%
auditorName
89.0%
materials
89.0%
…
…
liabilities (creditors)
75.0%
currentAssets
64.0%
realEstate
60.0%
receivables
52.0%
tax
41.0%
What does this table tell us and what are the current hurdles?
The results paint a clear picture: The model achieves remarkably high accuracy values for clearly defined master data or values, which are often prominently and relatively uniformly shown in annual reports. These include, for example, capital, equity, employees, cash or the currency symbol. Fortunately, hallucinations – for example inventing numbers that do not exist in the document – were not a significant problem in our tests. If errors occurred, it was usually due to misinterpretations of existing figures and not to their free invention.
It becomes more difficult for the model with more complex key figures. This is where the limitations of the current approach become apparent, especially when it comes to semantic fuzziness and varying levels of detail. Many balance sheet items can be defined, named, or broken down differently in reports. Terms such as “total assets” are not always clear – does it mean the balance sheet total before or after deduction of certain items such as goodwill, for example the intangible value?
The exact definition of current assets, receivables or liabilities varies between companies and reporting standards. This is where the model sometimes reaches its limits in deducing the exact definition valid in the respective report from the immediate context alone.
The dependence on layouts and the placement of information also plays a role. Some assets, such as realEstate (real estate assets), are often not prominently found on the main pages of the balance sheet but are hidden in detail in the “Notes to the Financial Statements” (Appendix). The model’s ability to correctly map such information across different pages and layouts is heavily challenged and results in lower accuracy scores.
Finally, some metrics require more complex interpretations or implicit calculations. The extraction of values such as tax is a good example of this. Different types of taxes (income taxes, sales taxes, etc.) and deferred taxes can often be spread over several sections. The correct aggregation and interpretation of this information is challenging, which explains the current accuracy of only 41% for this metric.
These quantitative results confirm our qualitative observations: the model is excellent at finding clearly labelled information. However, it reaches its limits when dealing with issues such as ambiguities in wording, widely varying or complex layouts, and the need to understand implicit knowledge or contexts across multiple text passages.
Another important aspect is the varying accuracy between different companies. The standard deviation of accuracy per company is about 9.2%. It is particularly striking that the accuracy of the large, individually designed reports from listed companies (PLCs) such as AstraZeneca (50%), Barclays (65%), HSBC (50%), Shell (70%) or Unilever (55%) tends to be significantly lower than average. Tests with excerpts of different lengths showed that the length of the context to be mastered is not a major difficulty for Gemini, we therefore assume that the uniqueness of the reporting structures of these groups is particularly challenging for the model. While Gemini Flash Lite handles layouts that are often created by smaller companies using off-the-shelf software, these complex cases are a bigger hurdle. One explanation could be that the reports that deviate from the standard rarely made it into Gemini’s training data.
Another recurring problem is the correct capture of units and scales. Missing or misinterpreting information such as “in thousands of £” or “millions of USD” will result in extracted values that are wrong by factors of 1,000 or 1,000,000. Here, robust downstream validation rules and targeted prompting are necessary to sensitize the model to these details.
The representation of negative numbers, which is often done by parentheses in annual reports (e.g. “(1.234)” instead of “-1.234”), also requires an explicit note in the prompt so that the model interprets this convention correctly and extracts the numbers with the correct sign. As already mentioned, hallucinations do not pose any major problems here (as it was with older models), it is the interpretation of the numbers that does not always succeed.
Finally, we are also faced with the classic trade-off between costs and performance in particularly complex cases. More sophisticated reasoning approaches such as Chain-of-Thought (CoT), in which the model makes its “thought steps” explicit, or the use of even larger and more powerful models (for example Gemini 2.5 Pro) could remedy the problems mentioned, especially when analysing the more complex reports.
However, these are currently often much more expensive. For example, Gemini 2.5 Pro is currently 16 to 32 times more expensive than the Gemini 2.0 Flash Lite we used. The common GPT-4.1, which is used in ChatGPT, also costs $2 per 1 million input tokens – about 27 times as much as Gemini 2.0 Flash Lite. Using our solution to process an average report from our 30-page test dataset costs only about $0.0007!
Conclusion: Gemini Flash as a powerful addition to the toolbox
Gemini Flash has proven to be a useful building block for us to take the extraction of structured data from annual reports to a new level and bring it into productive use at North Data. It does not necessarily replace the entire classic pipeline (as our OCR pre-filtering shows), but it does provide a powerful, integrated alternative to the core process of intelligent data extraction and structuring.
The ability to understand layouts, work within a larger context, and deliver structured outputs significantly reduces complexity and maintenance compared to traditional, multi-tiered approaches. The challenges remain, but the progress is clear and opens new opportunities for automated financial data analysis.
We are excited to see how this technology will develop further and what new solutions will emerge. Have you had similar experiences or developed different strategies? Share your thoughts with us!
This blog post was written with the support of Gemini 2.5 Pro.
]]>leonardThieleCode Generation using Java Annotation Processing2025-05-21T00:00:00+00:002025-05-21T00:00:00+00:00https://blog.cronn.de/en/java/codegeneration/2025/05/21/annotation-processing-code-generationIntroduction to code generation
Developers often find themselves confronted with writing the same type of simple code over and over again. Over time, some options were designed to reduce the time needed for writing trivial code. IDEs can automatically generate getters and setters or even apply custom templates that can be used for code generation. Elaborate tools like the OpenAPI Generator 1 are able to create the groundwork for client and server code in REST-based communication by using the interface specification as input, and even more recently elaborate AIs have been launched with this purpose in mind. In general, there are two different types of generating code: one time generation, like the getter and setter creation from IDE, and continuous generation, like the OpenAPI generator. In the latter, a change of interface specification directly results in changes in the generated code, and thus specification and code remain in sync.
Java annotation processing, which was introduced in Java 1.6, is another example of continuous generation. The main idea is that a code generator operates on specific parts of the code which is marked by annotations. These annotations are then processed in the generator, where new code is generated based on the annotated code and the annotations themselves. One of the most prominent frameworks that incorporates annotation processing is Project Lombok 2 which, among other features, has the option of generating getters and setters via annotation processing. The advantage of annotation processing is that the new methods are only created in the generated code and are not present in the actual versioned code, which in turn is more precise and contains less trivial boilerplate code. Furthermore, the generated code does not become obsolete and thus requires no maintenance.
Using an existing annotation processor
An annotation processor is in most cases already present if one is using third party libraries. The process of using it as code generator is easily described through the following example: suppose you want to map an object of type Company to its DTO CompanyDto. MapStruct 3 enables simple mapping of different types through generated classes which are described by annotations on an interface used as base.
Let us look at a Definition of a MapStruct mapper for a Company object to CompanyDto:
In order to use an annotation processor (in this case MapStruct) it is necessary to inform the build tool that such a processor is present and should be used. Gradle, for example, employs the keyword “annotationProcessor” for this, as is shown below.
Using the above definition MapStruct then creates an implementation for the interface using the information given through the annotations. The output for this is shown below.
Through annotation processing, an interesting aspect of the Java compilation step becomes visible. Normally, the compilation to bytecode starts with the parsing step, continues with an analyzing step and ends with the bytecode generation (note that this is an oversimplification for the needs of this article). Annotation processing is directly incorporated into this process. After the parsing step, all relevant annotations are processed by processors and if new code has been generate the parsing step is restarted. By repeating these steps in multiple rounds it is possible to generate code in one annotation processor which itself contains annotations which may trigger further processors in following rounds. This is nicely illustrated in the OpenJDK article on Compilation Overview 4.
The compilation process contains a repetition in case annotation processors generate new source material.
Custom code generator for annotation processing
The usage of existing annotation processors from third party libraries is already a big improvement for typical situations. However, the more interesting application is the development and use of custom generators. For this purpose, Java offers the javax.annotation.processing.Processor interface 5, which is already implemented in the abstract class javax.annotation.processing.AbstractProcessor. When creating a custom annotation processor either this interface has to be implemented, or the abstract class has to be extended in order to inform the compilation unit to use it. Through this, the custom processor inherits, among others, the methods getSupportedAnnotationTypes and process.
One of the first steps in creating a custom annotation processor is to tell the compilation unit, which annotations are handled by this processor. When inheriting from AbstractProcessor, instead of implementing getSupportedAnnotationTypes with a custom implementation, the supported annotations can be configured with the annotation @SupportedAnnotationTypes, which is used on the processor itself. Here, it is possible to use existing annotations as well as custom annotations specifically created for use with this processor. It is even possible to use wildcards for this.
The following example shows a custom annotation and how this is used in a custom annotation processor.
The process method is the one which is called by the compilation unit and where the actual generation happens. A set of all configured annotations and a RoundEnvironment for the current processing round are given as parameters. In order to get all elements that are currently annotated with the configured annotations, the round environment can be used by calling its method getElementsAnnotatedWith(…). Depending on the target, on which the annotation is specified, the returned elements may be of different element types like classes, fields or methods (e.g. in the upper example for @org.example.Builder the target ElementType.TYPE was used, which specifies classes, interfaces, enums and records).
For the actual Java file creation, a Filer6 instance can be used, which already has information about the build location for newly created files. Additionally, to the RoundEnvironment mentioned above, when inheriting from AbstractProcessor, a ProcessingEnvironment also exists, which can be accessed from child classes and be used in order to get such a Filer instance for creating new source files.
The final code that is generated by the processor, is just text that is written with the file writer of the filer instance. Therefore, it can be created in different well-known ways, e.g. by using string concatenation, StringBuilders or multi-line strings with formatters. However, if its content gets too complex, dedicated frameworks like 7 or more elaborate techniques like StringTemplates 8 are advised. The custom code generator in our example code 9 builds up on StringTemplates and shows some of the capabilities there. As mentioned previously, the generation process repeats itself in the case of newly created files also containing annotations for which annotation processors exist.
As described above, it is important to note that the complete annotation processing happens during the compilation step. If debugging is desired it is therefore necessary to add debug information to this, for example in the case of Gradle, by adding the -Dorg.gradle.debug=true flag to the current Gradle task. Through this, it is possible to use typical debugging tools, which make the development of such a code generator as simple as regular code.
In order to use the custom annotation processor during compilation of the target code, the compiler has to be informed about the existence of a processor to be used. There are different ways to achieve this, ranging from specific javac options like javac -processor …, to maven plugins. It is also possible to register it in the meta information of the build jar file in a file typically named META-INF/services/javax.annotation.processing.Processor, where each annotation processor is listed line by line. This is also the solution used in our example code. To make this process even easier, Google AutoService library 10 automatically creates such a file (interestingly enough, by using annotations and generating the file through annotation processing).
Many possibilities exist for automatic generation of simple code in Java. This article presented Annotation Processing, which is easy to use and deeply integrated in the Java environment. Potential applications range from builder classes, object mappers between different domain models, (fluent) setters and getters, automatic generation of constructors and boilerplate methods such as toString() and hashCode(). All of which can be used by adding a single annotation to the target code. Our example code 9 demonstrates the usage of existing third party libraries as well as the creation of custom annotations and generators. Due to the mentioned versatility and ease-of-use annotation processing is a powerful tool in the Java ecosystem.
Project Lombok Note: unlike typical annotation processors, in order to fulfill all its goals, Project Lombok directly manipulates the .class files instead of creating new .java files first ↩
]]>kevinKeulHandling of the ‘this-escape’ warning in JDK 212024-08-13T00:00:00+00:002024-08-13T00:00:00+00:00https://blog.cronn.de/en/java/2024/08/13/this-escapeJDK version 21 introduced a new rule to the Java linter. According to this rule it is not permitted to call an overridable method within the constructor of a class 1. If this rule is disregarded and the Java code compiled using the -Xlint:all or -Xlint:this-escape flag, this leads to the following this-escape warning:
warning: [this-escape] possible `this` escape before subclass is fully initialized
The addition of the new rule to the Java linter in JDK 21 is a good improvement as it helps prevent code smell. It has long been recommended to avoid calling overridable methods from the constructor 23. However, as an analysis 4 of some well-known open source projects shows, there are still places in the code where the recommendation is forgotten or ignored. Even in our own projects the upgraded Java linter was also able to find a few places that did not follow the recommendation.
In this article, we will briefly look at why no overridable methods should be called in the constructor. The following three sections show approaches that were used to resolve the warning in our projects.
In the following, it is assumed that the code shown is always compiled with the flag -Xlint:all, even if this was not explicitly specified. The complete code is available in this GitHub repository.
Origin Story
The rationale for the this-escape warning is explained below. Using an example, let’s take a look at the class Person. The class has an instance variable name and a public non-final method greet(). The greet() method is called in the constructor of the class. The code compiles fine with JDK 17, but when compiling with JDK 21, the Java linter issues a this-escape warning.
The Person class itself is unproblematic, but as soon as the class is extended, it can lead to errors that are difficult to find. The Java linter warns of this with the this-escape warning. To be able to provoke an error, we also create the class Musician as an extension of the class Person. The class Musician adds another instance variable, instrument, and overrides the method greet().
publicclassMusicianextendsPerson{privatefinalStringinstrument;publicMusician(Stringname,Stringinstrument){super(name);this.instrument=Objects.requireNonNullElse(instrument,"triangle");}@Overridepublicvoidgreet(){super.greet();System.out.println("I heard you play "+instrument+". Awesome!");}}
What is now being output when a new Musician object is created with the new Musician("Jimi", "guitar") statement? When an instance of Musician is created, the constructor of Person is called in the constructor of Musician. In the constructor of Person, the instance variable name is initialized and then the method greet() is called. The variable instrument is then initialized within the constructor of the class Musician. The statement results in the following output:
Hello Jimi!
I heard you play null. Awesome!
The overridden method greet() is called from Person even before Musician has been fully instantiated. This results in the value null being output for instrument, although instrument can never have the value null after instantiation of the object Musician. The reason for the incorrect output is quickly apparent in the example. Nevertheless, it shows that a class should not call any overridable methods of its own class in the constructor, as the class cannot ensure that it is in a consistent state when the method is called. It follows that the greet() method should not be both overridable and called by the constructor at the same time.
It should be noted that the error in this example seems obvious as we have looked at a simple example to explain the situation. In practice, the error in an extensive class within a complex class hierarchy with further inheritance and nesting in connection with concurrency can be considerably more difficult to locate.
Three approaches
The following three sections present ways of preventing or circumventing the calling of an overridable method from the constructor.
Using the keywords final, private or static
The most direct way to prevent the this-escape warning is to prohibit the overwriting of all methods called by the constructor. This can be achieved in Java with the keywords final, private, and static. If a class is declared as final, it is no longer possible to extend it. Accordingly, none of its methods can be overwritten. The declaration of a method as final, private or static ensures that it is the method alone which cannot be overwritten.
We can use these keywords to fix the incorrect output of the Person and Musician classes from the last section in various ways. In the following, we first declare the greet() method of Person as final to satisfy the Java linter.
publicclassPerson{privatefinalStringname;publicPerson(Stringname){this.name=Objects.requireNonNullElse(name,"stranger");greet();}publicfinalvoidgreet(){// Method is now finalSystem.out.println("Hello "+name+"!");}}
This makes it so that the Musician class can no longer overwrite the greet() method. Instead, a separate method printInstrument() is defined in the Musician class, which is now responsible for the output of the instrument. For this approach to work, we must define that the class Musician should not be extended by any other class, so we add the keyword final to the declaration of the class – otherwise, the Java linter would give us a this-escape warning here too.
publicfinalclassMusicianextendsPerson{// Class is now finalprivatefinalStringinstrument;publicMusician(Stringname,Stringinstrument){super(name);this.instrument=Objects.requireNonNullElse(instrument,"triangle");printInstrument();}publicvoidprintInstrument(){System.out.println("I heard you play "+instrument+". Awesome!");}}
After the changes, the statement new Musician("Jimi", "guitar") leads to the following output:
Hello Jimi!
I heard you play guitar! Awesome!
However, it is not always possible to declare a class as final or method as final, private, or static. If the class is managed by a dependency injection framework, such as Spring or Quarkus, the call of overridable methods from the constructor can usually be bypassed in another way. We will look at these in the next section.
Usage of the annotation @PostConstruct
Although we will be using Spring in the following examples, the approach can also be used for other dependency injection frameworks that implement the Jakarta Contexts and Dependency Injection specification or the Jakarta Annotations specification. Part of the Jakarta Annotations specification is the annotation @PostContruct, which is essential for the approach presented here. Using the annotation, we can link into the life cycle of a bean managed by Spring. In the case of @PostConstruct this happens, as the name suggests, after the constructor has been executed and the bean has been fully initialized. This makes it possible to move the call of an overridable method from the constructor to a safe place. Spring offers other ways to insert custom code into the lifecycle of a bean, but the use of @PostConstruct is the recommended 5, so only this will be discussed here.
In order to illustrate the use of @PostConstruct, let us extend our earlier example. In the previous example, the instrument triangle was assigned to each musician if no instrument was specified. We want to optimize this a little by making it possible to connect an external resource. This should provide a mapping between known musicians, represented by their name, and their instrument. The mapping should be saved in a cache for faster access. The use of the cache is shown schematically in the following listing:
Stringname=getName();// Get name of a musician from somewhereStringinstrument=getInstrument();// Get instrument from somewhereif(instrument==null){/*
musicianInstrumentCache contains a mapping of the form:
Jimi -> guitar
Miles -> trumpet
Ludwig -> piano
...
*/instrument=musicianInstrumentCache.getInstrumentFor(name);}Musicianmusician=newMusician(name,instrument);
We create two classes for the implementation. The abstract class MusicianInstrumentCache contains a simple cache, which was realized as a Map with the mapping musician name ⟼ instrument, and calls the method updateCache() in the constructor. The updateCache() method is to be used by the specializations of MusicianInstrumentCache (see below) to read in an external resource and update the cache. The following applies to the updateCache() method:
Calling the method should enable other classes to update the cache at runtime . The method should therefore be public.
For different types of resources, such as external files, databases, etc., it should be possible to create different specializations of MusicianInstrumentCache, which override the updateCache() method in line with the resource used. Therefore, the method should be abstract and cannot be declared as private, final, or static.
The implementation of the abstract class MusicianInstrumentCache is given below. The linter issues a this-escape warning when the class is compiled, as the abstract method updateCache() is called in the constructor.
publicabstractclassMusicianInstrumentCache{protectedstaticfinalMap<String,String>cache=newConcurrentHashMap<>();publicMusicianInstrumentCache(){System.out.println("MusicianInstrumentCache.init()");updateCache();// Calls overrideable method, causes this-escape warning}publicabstractvoidupdateCache();// Should be public and abstractpublicStringgetInstrumentFor(Stringname){returncache.get(name);}}
Before we address the problem, let’s look at a specialization of the class MusicianInstrumentCache. The class FileBasedMusicianInstrumentCache shows a possible specialization of MusicianInstrumentCache. The class should read the mapping from a file via the Spring-injected ResourceLoader, then proceed to write it to the cache. To keep the example short, the reading of the file and the writing to the cache is only implied in the code.
@ComponentpublicclassFileBasedMusicianInstrumentCacheextendsMusicianInstrumentCache{privatefinalResourceLoaderresourceLoader;privateStringmappingResource="classpath:mapping.csv";publicFileBasedMusicianInstrumentCache(ResourceLoaderresourceLoader){System.out.println("FileBasedMusicianInstrumentCache.init()");this.resourceLoader=resourceLoader;}@OverridepublicvoidupdateCache(){System.out.println("FileBasedMusicianInstrumentCache.updateCache()");// Logic for importing mapping and adding it to the cache. Briefly,// represented by the following lines without exception handling:Resourceresource=resourceLoader.getResource(mappingResource);Stringcontent=resource.getContentAsString(StandardCharsets.UTF_8);Arrays.stream(content.split("\n")).map(line->line.split(",")).forEach(mapping->cache.put(mapping[0],mapping[1]));}// getter and setter}
It should be noted that if the updateCache() method of the FileBasedMusicianInstrumentCache class is called in the constructor of the MusicianInstrumentCache class, then the resourceLoader has not yet been set. This is because, as described in the section Origin Story, the constructor of the extending class FileBasedMusicianInstrumentCache calls the constructor of the class MusicianInstrumentCache as the first statement, even if the call via super() was not explicitly specified in the Java code. This can also be seen in the output, where FileBasedMusicianInstrumentCache.updateCache() is written to the console before FileBasedMusicianInstrumentCache.init():
Fortunately, the error and the this-escape warning can be fixed with the annotation @PostConstruct without major adjustments, so that the overridable method updateCache() is no longer called before the object has been completely initialized. It is sufficient to annotate the updateCache() method in the MusicianInstrumentCache class with @PostConstruct. The call of the method updateCache() can be removed from the constructor, as Spring is now responsible for the call. The class FileBasedMusicianInstrumentCache can remain unchanged, as Spring checks whether a method with @PostConstruct is annotated in a superclass and adopts the behaviour for the subclasses.
When the application is started, the constructor MusicianInstrumentCache is still called when the class FileBasedMusicianInstrumentCache is initialized, but the method updateCache() is no longer called in the constructor; instead, the constructor of FileBasedMusicianInstrumentCache is completed first. Only after FileBasedMusicianInstrumentCache has been completely constructed does Spring call the updateCache() method annotated with @PostConstruct. This results in the following output:
The procedure with @PostConstruct makes it possible to link the use of overridable methods to the creation of the object without the problems that may result when calling from the constructor. However, this requires the use of a dependency injection framework that supports the annotation @PostConstruct.
The previous two sections described two small tweaks to satisfy the linter. In the next section we will look at another way of dealing with the warning.
Revise the class design
Sometimes the this-escape warning can also serve as a suggestion to re-evaluate the class design. Depending on the result of the evaluation, the necessary changes may have a greater impact on the structure of the code than was the case with the other two methods. We once again take up the example from the previous section to show what an adaptation of the class design could look like.
In the last section, the two classes MusicianInstrumentCache and FileBasedMusicianInstrumentCache were created, with the latter extending the former. Due to inheritance, the method updateCache() had to be public and overridable, which ultimately led to the this-escape warning. In the following, the class design should use composition instead of inheritance.
The functionality of the class MusicianInstrumentCache is split for this purpose. The management of the cache will remain the task of the class MusicianInstrumentCache. The import of an external resource is outsourced to the class FileBasedMusicianInstrumentImporter. The class FileBasedMusicianInstrumentImporter also receives a reference to an instance of the class MusicianInstrumentCache. Below, the old, inheritance-based class design is compared to the new class design in a UML class diagram.
The following listing shows the code of the new class MusicianInstrumentCache. The class has two methods, one for reading and one for writing the cache. MusicianInstrumentCache was annotated with @Component, as it is managed by the Dependency Injection Framework, and is to be injected into FileBasedMusicianInstrumentImporter.
The code of the class FileBasedMusicianInstrumentImporter is shown in the following listing. The annotation @PostConstruct is no longer required as it is now sufficient to declare the class as final.
@ComponentpublicfinalclassFileBasedMusicianInstrumentImporter{privatefinalMusicianInstrumentCachecache;privatefinalResourceLoaderresourceLoader;privateStringmappingResource="classpath:mapping.csv";publicFileBasedMusicianInstrumentImporter(MusicianInstrumentCachecache,ResourceLoaderresourceLoader){this.cache=cache;this.resourceLoader=resourceLoader;importMapping();}publicvoidimportMapping(){// Logic for importing mapping and adding it to the cache. Briefly,// represented by the following lines without exception handling:Resourceresource=resourceLoader.getResource(mappingResource);Stringcontent=resource.getContentAsString(StandardCharsets.UTF_8);Arrays.stream(content.split("\n")).map(line->line.split(",")).forEach(mapping->cache.put(mapping[0],mapping[1]));}// getter and setter}
The example is intended to provide an impression of what a revision of the class design could look like. However, this does not always have to involve a switch from inheritance to composition. It could also involve extracting/moving methods, or using a creational pattern to resolve the call of an overridable method from the constructor.
At this point, we have looked at all the approaches that were used to upgrade our project. The next section summarizes the main points of this article.
Summary
In this post, we described the motivation behind the Java linter’s this-escape warning and showed three ways to prevent said warnings. The possibilities are listed below:
Use of the keywords final, private, or static;
Use of the annotation @PostConstruct;
Revision of the class design
It is not always the case that all three approaches are applicable. Sometimes a combination of multiple approaches is necessary to resolve the warning. The best way to deal with the warning must be decided on a case-by-case basis. In most cases the first or second approach should be sufficient; however, the use of the second approach requires that the affected class is managed by a dependency injection framework such as Spring or Quarkus. Reworking the class design should always lead to success, but is also the most time-consuming.